
Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
-
A four-phase framework for evaluating AI search
-
How to build a golden set of queries that predicts real-world performance
-
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
This is a guest post by Kun Chen, a former L8 principal engineer at Meta, Microsoft, and Atlassian, where he led development of Rovo Dev, Atlassian’s AI SDLC product. He has since left big tech to build solo and has gone all-in on agentic engineering. Below, he walks through his complete setup, step by step. You can follow him on X and subscribe to him on YouTube, where he shares his agentic engineering workflow, the open-source tools he builds, and his take on AI and software craft. Over to Kun.
Hi everyone, Kun here. For context, I spent years driving agent adoption among tens of thousands of engineers at all levels, both within my company and across many customers’ engineering organizations. Going solo has actually let me lean into agents even more.
Here’s the difference using agents has made to my productivity: shipping 30+ high-quality PRs that meet my own bar used to be hard to imagine, and it’s now a slow day. I’ve reached what feels like a constant flow state, where the quality and speed of my thoughts is the only bottleneck left.
All of this didn’t come from a single trick or using some hyped tool. It came from a long and often messy process of figuring out what actually works in the real world versus what just sounds good in a demo. The short version is that I have now stopped writing most of the code myself and started acting like an engineering manager directing a team of agents. I stay at the level of deciding what to build and whether it’s good, and I’ve built tooling to handle almost everything in between.
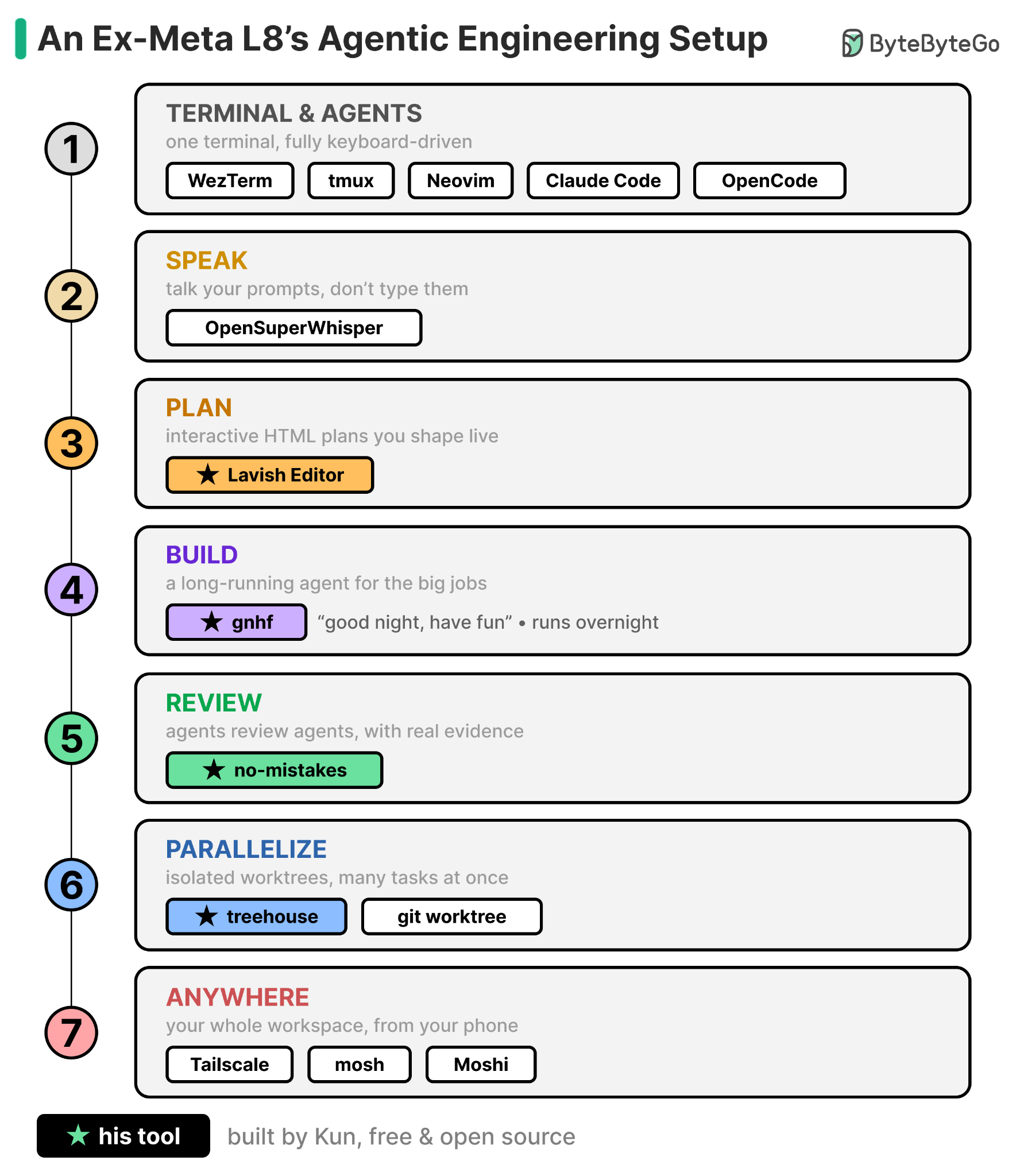
The interesting part of this journey is all the friction I had to remove to reach this point. Therefore, in this post, I’m attempting to share everything I do, step by step, for both my professional and personal projects.
If you’re on the same journey of making your work with agents more productive and enjoyable, I hope this gives you a head start and shortcuts some of your own exploration.
First, what I’m sharing here is my personal setup. What works well for me may not be the best fit for everyone. I’m sharing my workflow as-is, mainly hoping it can be a useful reference or inspiration for what to explore, even if you don’t end up using the same tools.
Second, I have no affiliation with any of the 3rd party products I mention in this post, and the tools built by me are all free and open source. I share these specific products because those are genuinely what I use in my setup. They are often not the only choice for the problems they solve, so I encourage everyone to research different options based on their interests and requirements.
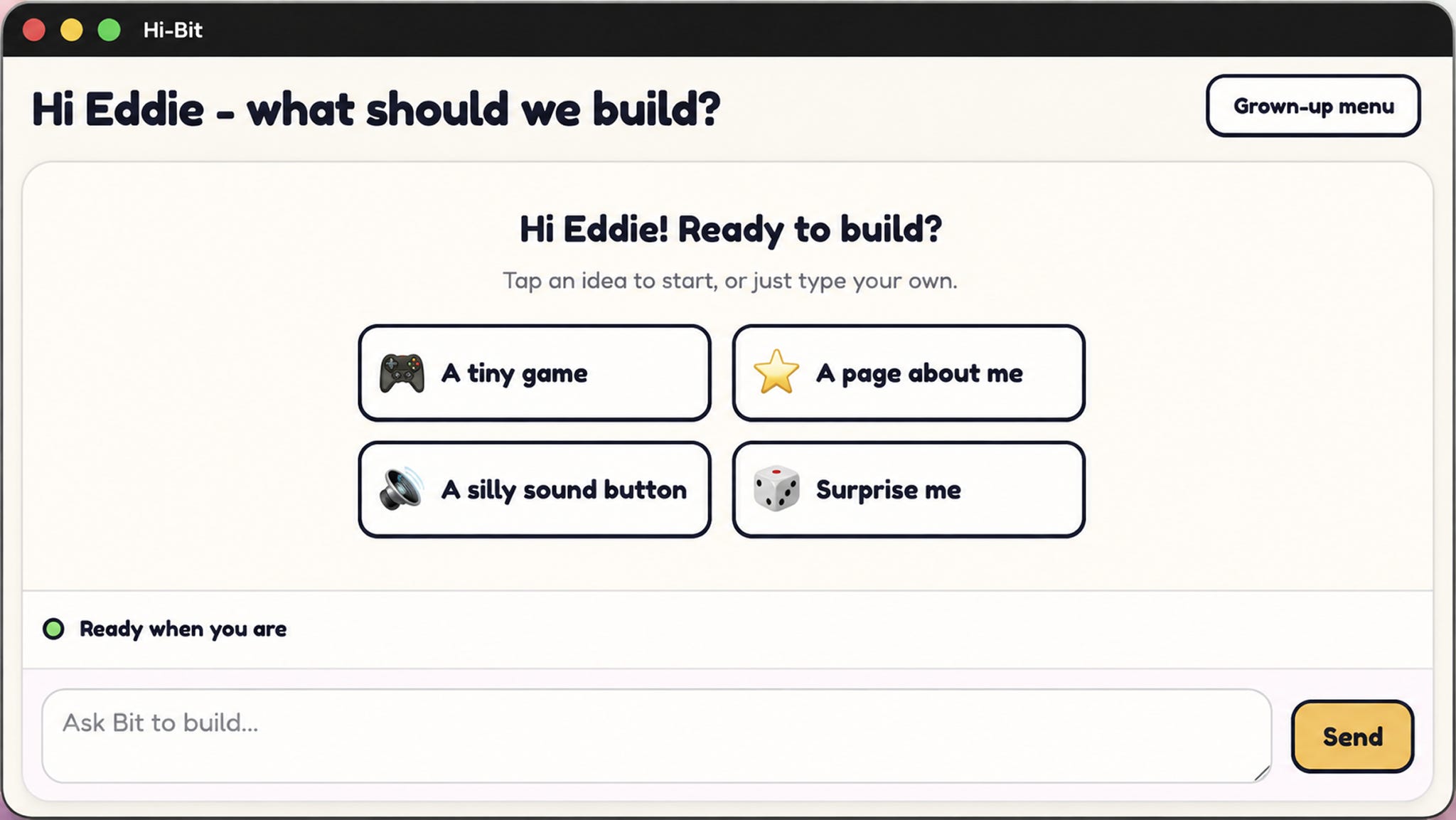
To make this post concrete and practical, I’ll walk you through my workflow using a real project I’m actively building. It’s called “Hi Bit”: an AI tutor I’m making for my son to teach him agentic engineering. In the rest of the post, I will follow the implementation of a specific image input feature in the Hi Bit project from the idea to merged PR so that you can get a first-hand look at my agentic workflow.

What happens when deterministic code hits the edge of its knowledge? In this live webinar, you’ll see a working plant health monitor built on Temporal’s entity workflow pattern where each plant is a long-running, crash-proof workflow that polls sensors, fires alerts, and falls back to GPT-4o only when the rules run out.
The architecture is clean: structured data first, AI second. The boundary is auditable. The state survives everything. Whether you’re building patient monitors, supply chain detectors, or any long-running process that occasionally needs a smarter answer, the patterns here translate directly.
There has been a constant debate in the developer community about terminal vs GUI.
I’m obviously biased because I started coding almost 30 years ago and built decades of muscle memory on top of a terminal-centric workflow ever since. But I did try GUIs every once in a while, from Visual Basic, Visual Studio, to Atom, and now the latest Codex app.
The reason I stick with terminals is very simple. I keep my flow and focus best when my hands never leave the keyboard. Some GUIs let you do everything via keyboard shortcuts as well, but they’re very inconsistent about it, which makes it hard to build strong muscle memory.
The terminal emulator I’ve been using for many years is WezTerm.
It’s the only terminal I’ve found that is highly performant, customizable, and works consistently even when I’m forced to use Windows. I run it as a single frameless window: no tabs, title bar, or status line, literally nothing else.

I use Claude Code for Anthropic’s models and OpenCode for everything else.
The CLI agent harnesses nowadays are quite commoditized, and you won’t really go wrong with any of them. Almost everything I share below works with any mainstream harness you can find.
In fact, I actually recommend avoiding the “fancy” gimmicks that only some agents have, such as auto-managed memory. They’re often designed to lock you into a particular vendor, when in reality you benefit a lot from being able to switch to whichever newer model works best, even if it comes from a different vendor. I try to keep my whole workflow agent-agnostic, so I have no switching cost. It’s far from clear which model will win in the end, and as a user, you’re in a much better position if you can work with any model available rather than being locked into one.
Neovim has been my primary editor for a long time, and it’s a critical part of staying fully keyboard-driven inside the terminal. You might ask, “But I use agents now. Why do I need an IDE?”
I use it to quickly examine the file system, review diffs, and make small edits when needed. A few plugins do most of the heavy lifting:
-
oil.nvim: navigate and edit the file system like a buffer
-
neogit: quickly review git status and diffs, and perform simple operations
-
snacks.nvim: I use its picker for finding files and grepping the codebase
I don’t let my terminal emulator manage tabs, because I manage all my sessions, windows, tabs, and panes in tmux instead. It’s one of the most powerful primitives in my whole setup, and it unlocks a few things at once:
-
Splitting my terminal window into panes the way I like
-
Driving the entire terminal experience from the keyboard
-
Persisting the working sessions and layout
-
Accessing the same session from my other devices (more on that later)
A popular alternative is Zellij, but tmux has worked well enough that I haven’t switched. As soon as I’m in, I create a split on the left for the agent and one on the right for Neovim, and I separate different tasks into different tabs that I keep track of along the top.
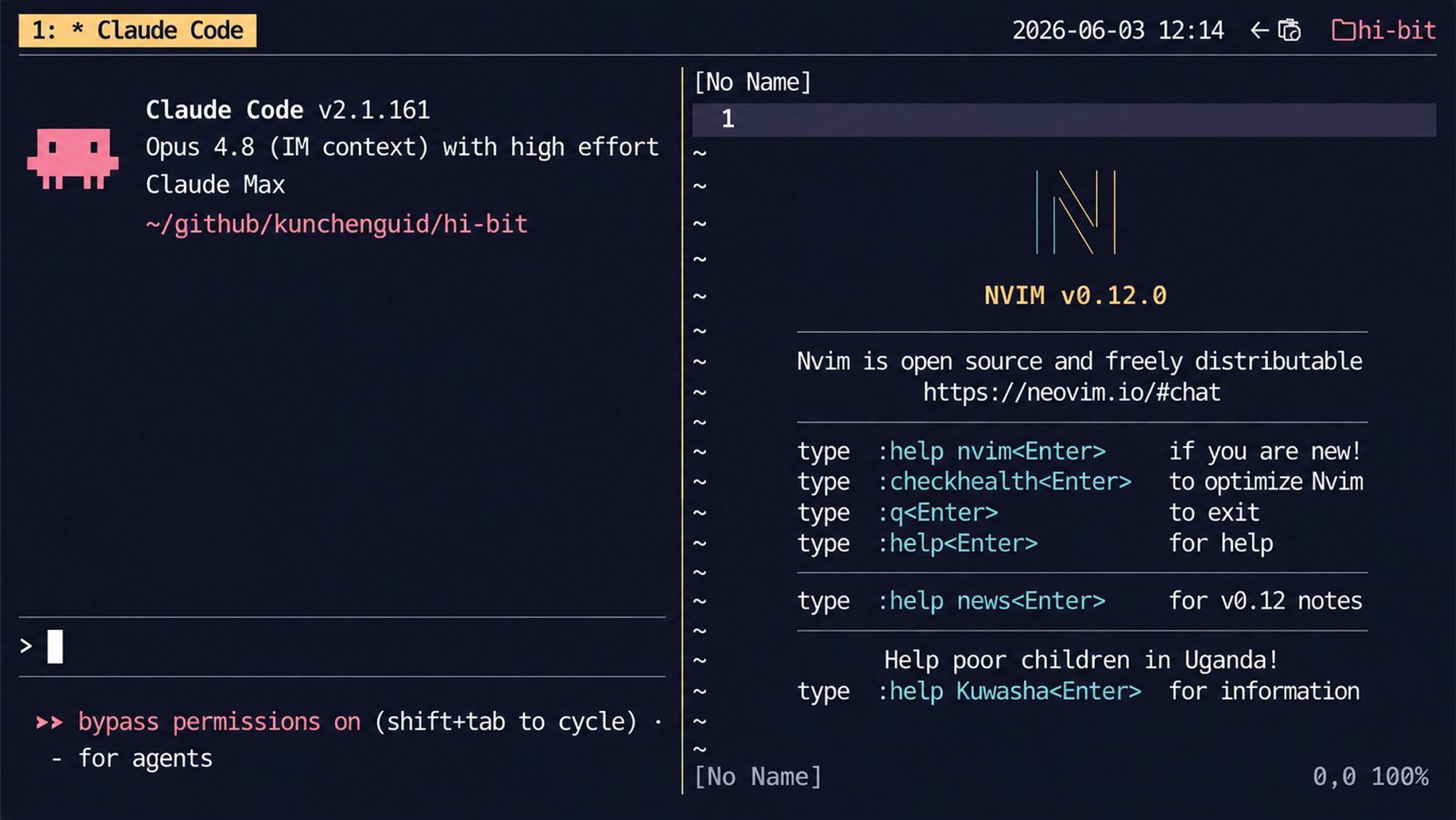
We’re now in the terminal, and the agent is waiting for instructions. All I have to do is write a prompt. Sounds easy, right?
Actually, how you write your prompts is one of the biggest levers on both the velocity of your work and the quality of the outcome. So let me share a few things that made a big difference for me.
Typing was my primary input method for decades. But over the last couple of years, speech recognition models have really changed the game. You can now run high-quality models locally on your Mac, for free, that generate output extremely fast.
You talk a lot faster than you type, so moving to voice as your primary input is one of the easiest ways to greatly improve your productivity. It applies to prompting your agents, but also to anything else that used to require typing. This post, for example, is mostly written by voice.
The solution I use is OpenSuperWhisper, which is completely free and runs the Whisper model (turbo v3 large) locally. I set a hotkey to trigger it, and now I can just talk wherever I could type. There are plenty of other free and paid options that give a great experience as well.
For many new tech leads and people managers, the first struggle is delegation. The same thing happens with how you interact with agents.
The most common mistakes I see people make about delegation to both humans and agents are:
-
asking for an action, not an outcome;
-
not explaining the “why.”
-
taking back control.
Take “rename this variable.” It’s a valid prompt, but it has a couple of problems:
-
The agent finishes in a few seconds and waits for you again. It barely saves more time than doing it yourself, and you’re still the bottleneck.
-
There’s no “why.” Do you want it renamed for readability? To follow a team convention? Because of a future plan you haven’t mentioned? Without the why, there’s no room for the agent to suggest something better, and it won’t know how to do it right next time.
If you were following a convention, a better prompt would be: “Let’s audit this part of our codebase and make sure our variable naming follows this convention <link_to_document>.”
That explains the rationale, gives the necessary context, and asks for an outcome instead of an action. The agent can run longer, get more done in a way that’s aligned with your goal, and respect that convention for the rest of the session instead of creating more problems for you.
The other failure mode is taking back control. When a mistake happens, people immediately think of doing it themselves. This happens to new tech leads working with a junior engineer. They could do the job faster by taking over, but in doing so, they make themselves the bottleneck and fail to scale. People hit the exact same wall with AI: they see an agent do something wrong and revert to doing it manually, and they never truly unlock the leverage agents offer.
The right approach is to give feedback and help the other party improve. With agents, this is actually easier. You can write directly into the agent’s memory file (CLAUDE.md or AGENTS.md), or ask the agent to reflect on its mistake and update that file so the same thing doesn’t happen again.
The feature I’m building right now is image input. I want the chat box in Hi Bit to accept a pasted image from the clipboard, or open a file picker or camera. This is a bit more than I think the agent can one-shot the way I want. In the beginning, I also didn’t know exactly where the button should go or what the attached images should look like.
This happens a lot: problems where I genuinely can’t describe the full solution up front. It could be a new project from scratch, a major refactor, or a big feature on an existing system. In those cases, I work with the agent to write a plan first.
There’s a school of thought in the agentic community that’s against technical planning. They prefer to “just talk to your agent” instead.
I went the other way, and here’s why. When you just talk to your agent, you have to stay in an interactive session. You get constantly pulled back into the conversation, and after a few rounds, it’s hard to keep track of what the actual plan is. A long wall of text in the terminal is also painful to parse and hard to give targeted feedback on.
Instead, I spend a concentrated chunk of time up front getting the plan into a confident state, so I can hand it off for a fully autonomous implementation without jumping back in until it’s done. That’s also what frees me up to run other tasks in parallel without constant context switching.
For a long time, I did this by asking the agent to write a proposal in a markdown file, then questioning it and iterating. That worked, but I have something better now. Inspired by an article on using HTML as interactive artifacts, I built a tool called Lavish Editor to collaborate with the agent on anything complex.
So instead of “draft a technical plan in a markdown file,” I say “draft a technical plan using npx lavish-axi.” Lavish guides the agent to render the plan as an interactive HTML page and opens it in my browser. It even encourages the agent to match the look and feel of the current project, so the plan for a UI feature looks visually consistent with the real app, which makes options far easier to judge.

A few minutes later, the agent had a plan open in my browser. It opened with the goal and context, flagged the decisions I’d need to make, and then laid out three UI options — a “+” button menu, an always-on button trio, and a smart-paste tile — each with pros and cons and the agent’s own recommendation.
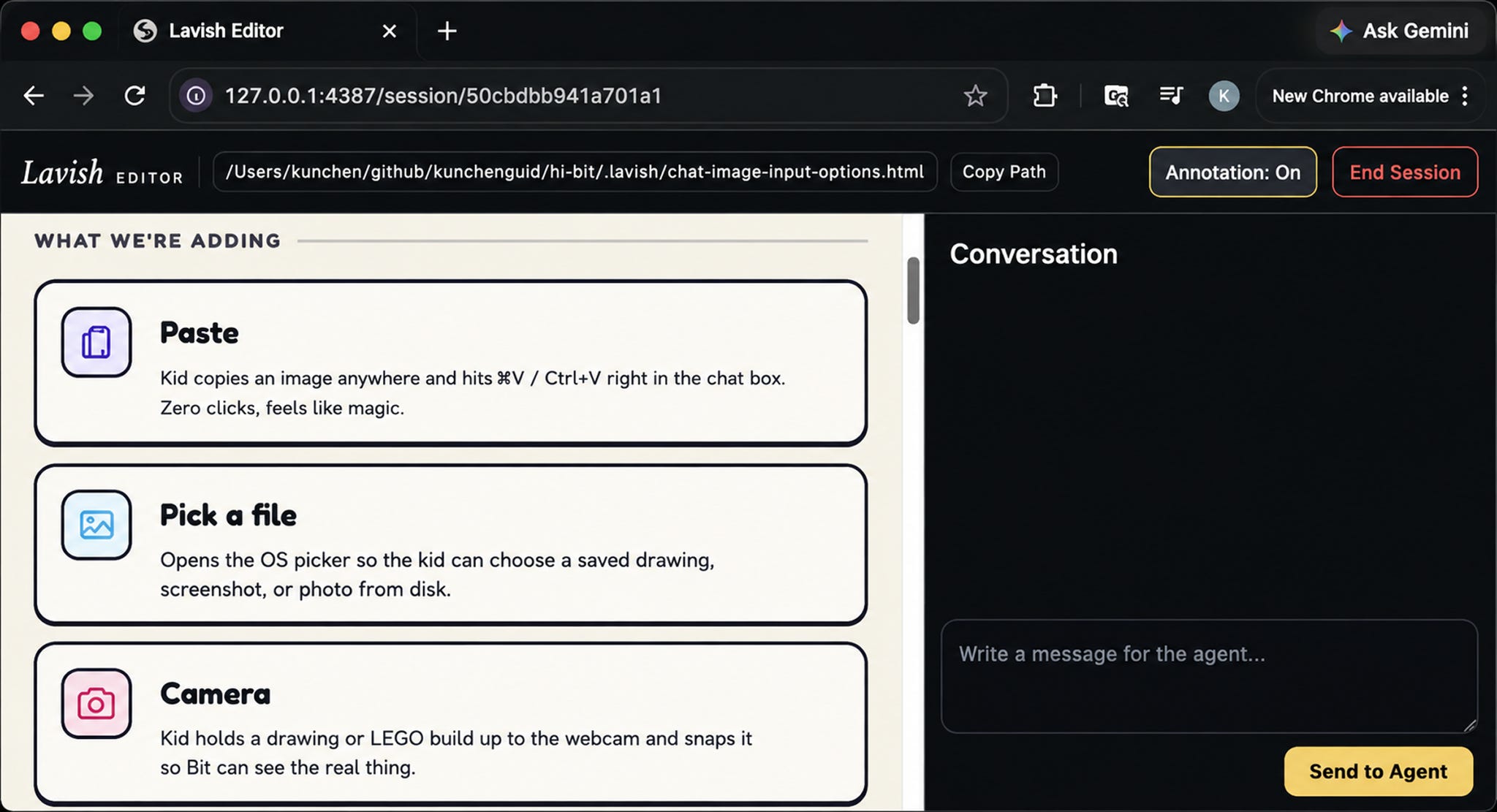
The real payoff is the interactive back-and-forth. I liked Option A’s tiny resting footprint, but not that its menu dropped down and stretched the chat area. Rather than writing a paragraph describing which element I meant, I just clicked that element in the page and annotated it directly: “Can we make it a floating overlay above the + button instead?”
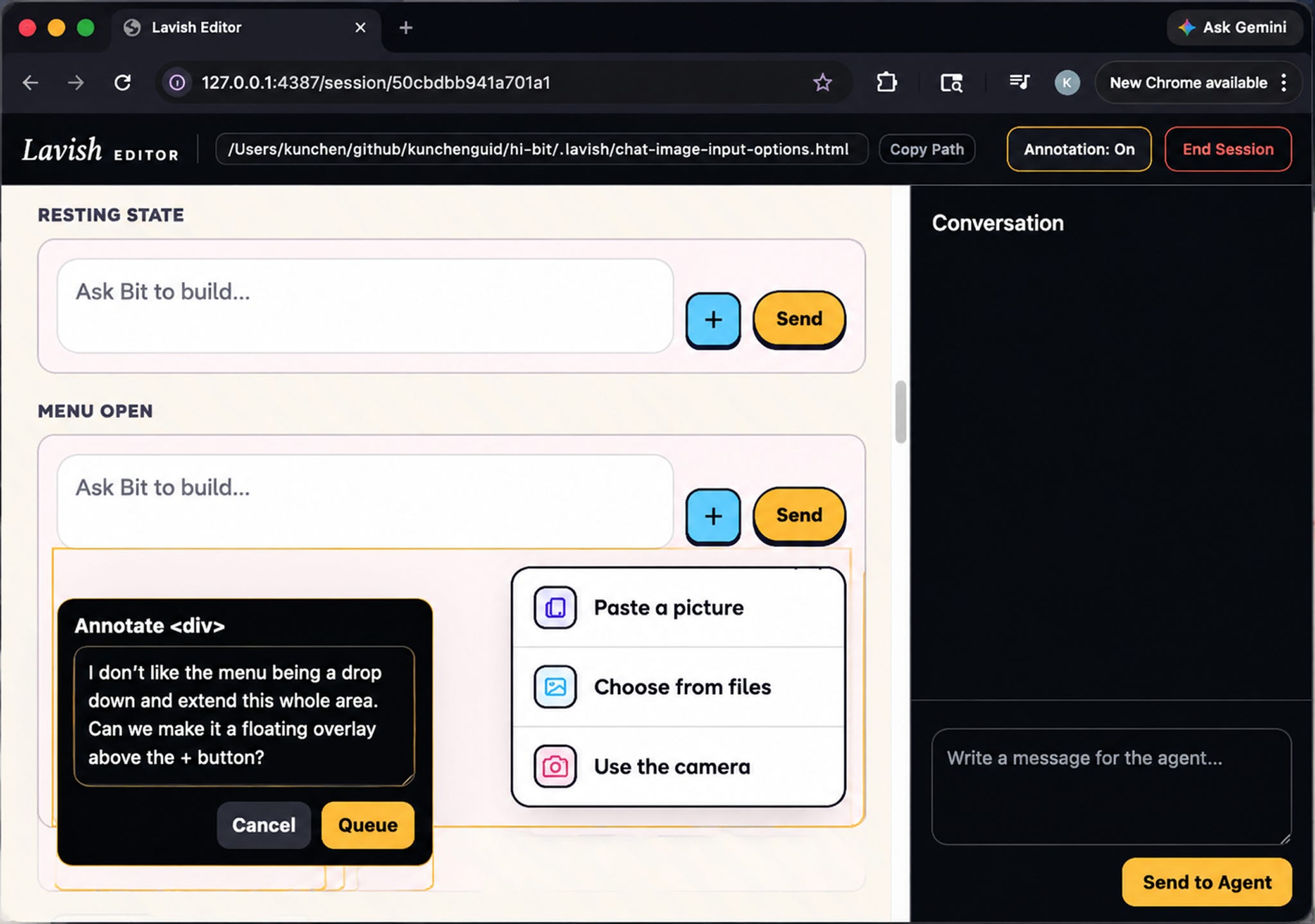
The agent came back almost immediately with exactly the revision I wanted, and I finalized the remaining decisions just by clicking buttons. Being able to interact with a plan this richly, instead of editing a markdown file, turned out to be a big productivity boost, and it’s not limited to planning. I now use Lavish for brainstorming, reviewing changes, data reports, and anything else that benefits from a visual artifact and tight back-and-forth. It’s been a game-changer.
Once the plan is clear, the implementation is fully autonomous, and there’s honestly not much for me to do except wait for the agent to ping when it’s done.
The one thing worth mentioning over here is that for every project, I spend a lot of effort making sure the agent can validate its own change end-to-end. As an example, for Hi Bit, I keep explicit instructions in the repo’s AGENTS.md for how to exercise the app, so changes like this get validated by the agent before they come back to me. I can often watch it test its own work in real time by driving the real app, attaching an image, and checking how the new button actually behaves.
Occasionally, a task is so complex that it doesn’t fit well in a single context window. If I just let the agent grind on it, it fills its context, fires off very large requests, and eventually compacts to free space, sometimes losing important context in the process. The newer /goal command in Codex and Claude Code helps a bit, but I’ve been using something better since well before it existed.
I call it good night, have fun: gnhf for short. It’s a dead-simple, long-running orchestrator I built for running big tasks overnight; you invoke it with gnhf <your objective>.
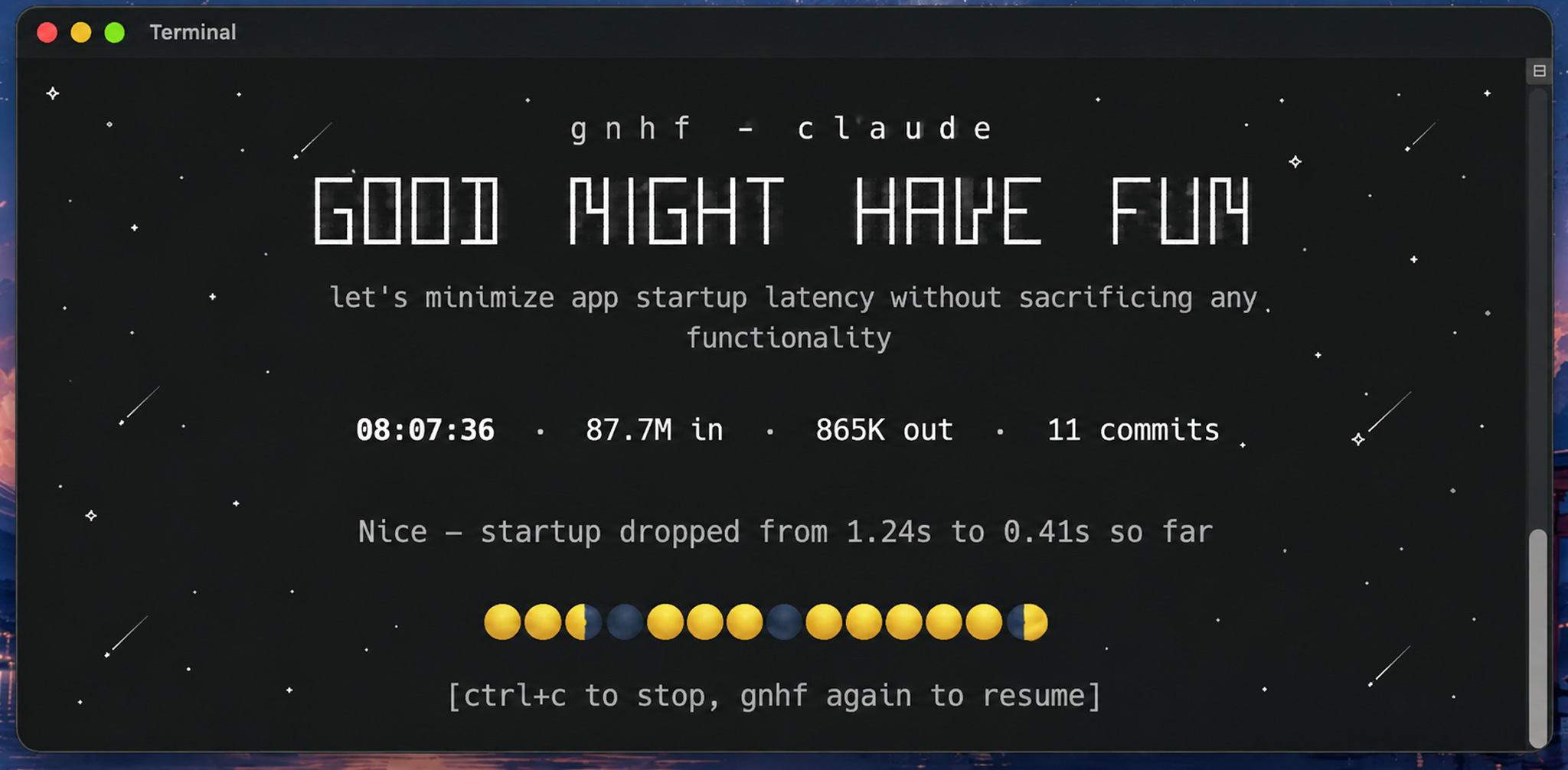
Under the hood, it works similarly to the Ralph Loop and Autoresearch patterns. It breaks the task into small steps, and each step runs in a fresh context window seeded with a common base context plus the learnings from previous steps. Failed attempts roll back automatically, and the next attempt takes the failure into account. I can also set a token budget so I don’t wake up bankrupt. When I come back, there’s a branch with well-organized commits and a notes.md file summarizing what was done.
I reach for gnhf in three kinds of situations:
-
Implement a massive plan: gnhf “fully implement this plan…”
-
Improve a measurable metric such as reducing lines of code, increasing test coverage, cutting startup latency, or page load time: gnhf “improve <this metric> while keeping product functionality unchanged.”
-
Run lots of offline experiments when you have an evaluator capable of scoring each attempt. For one project, I generated a game map by running 50+ layout experiments and scoring each through a gameplay simulation. Babysitting those by hand would have taken weeks.
Back to the image task: the agent has done the work, and it has produced a big change. Now what? This is where many people hit the real bottleneck: code review. There’s simply too much code to read, and reviewing it isn’t the fun part of the job.
I’m increasingly convinced that working with agents means acting like an engineering manager. Most managers rarely review code directly. They have the team review each other’s work, and before anything ships, they ask for evidence that it actually works. It’s the same with AI, except the developer is the manager and the agents are the team. You have to get good at using agents to scrutinize agents’ code, get them to self-correct, and get them to produce artifacts that demonstrate the feature really works.
I’ve experimented a lot here, and a few things turned out to matter most:
-
Run the reviewer agent in a fresh context window. If you review in the same session that wrote the code, the agent is biased by what it just did and assumes it was intended. It’s like asking someone to check their own work. They’ll catch some things, but it’s far weaker than a real peer review.
-
Escalate ambiguous, product-changing decisions to the human. Reviewers make mistakes, too. If you let the agent auto-fix every finding as if it’s all valid, it can drift into rabbit holes away from what you actually want. Keeping those decisions with the human keeps you in control of the ambiguity.
-
Force end-to-end evidence. Today’s frontier models lean heavily on unit tests to validate changes, probably because of how they’re trained. But I’ve seen countless cases where every unit test passes, and the product is still buggy. You have to make the agent prove the change works E2E.
I packaged all of this into an open-source tool I built called no-mistakes, which I now run on the image change. First, I use the neogit plugin to quickly scan the diff and make sure it’s roughly aligned with what I asked. Sometimes an agent goes in a completely wrong direction, and that’s obvious at a glance.
If it looks reasonable, I run no-mistakes -y and it handles the rest: commit with a conventional message into a descriptively named branch, rebase onto the latest main and resolve conflicts, spin up agents to peer-review and self-correct obvious bugs, test the change E2E and produce evidence, close documentation gaps, fix linting, push, open a well-structured PR, and babysit CI until it’s green.
All of it runs autonomously except for the decisions it deliberately escalates to me.
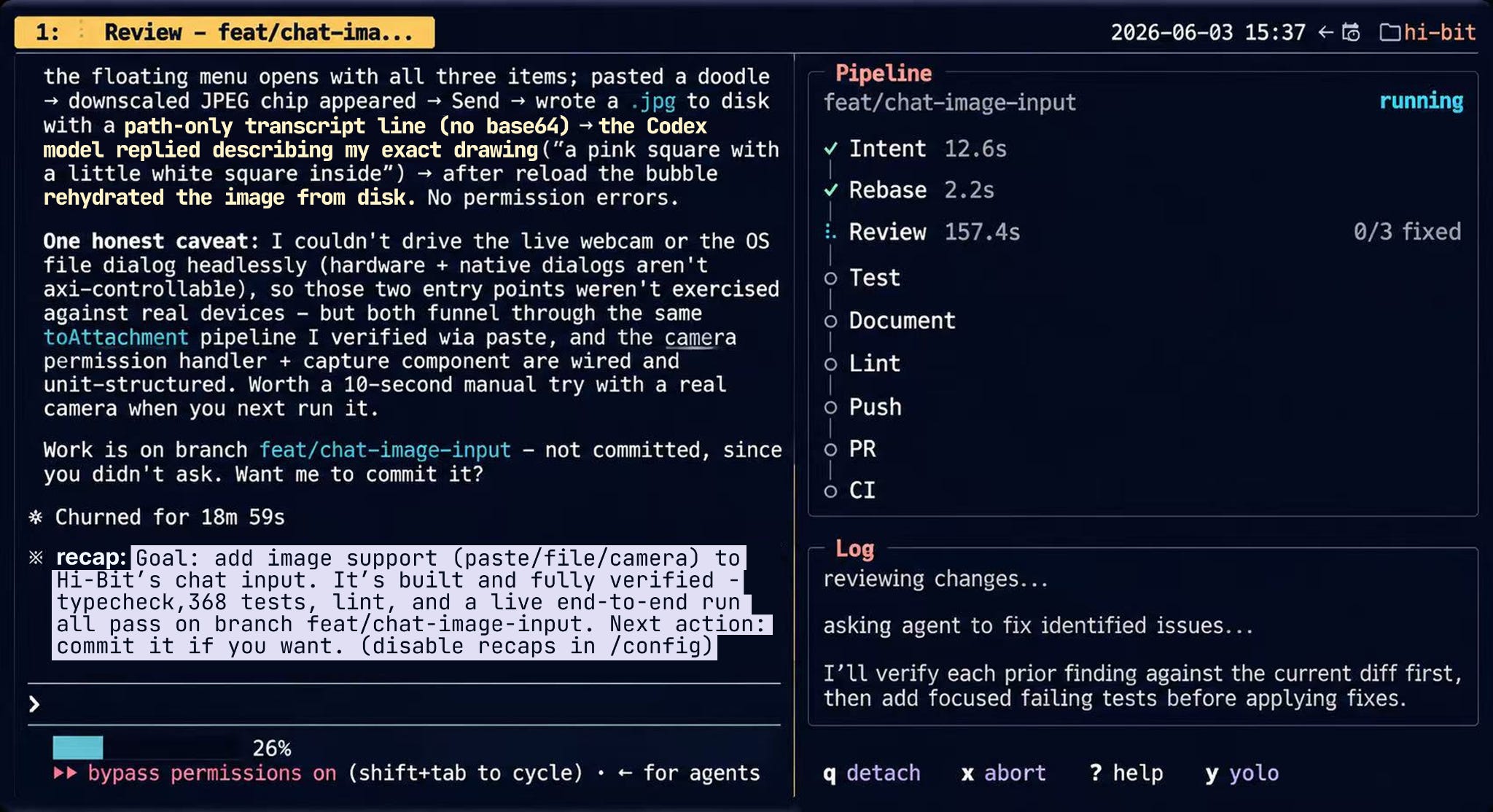
This validation pipeline has become one of the most critical pieces of my whole workflow. My own stats show that 68% of the changes I pushed through the no-mistakes tool had bugs in them. I genuinely can’t imagine what my codebase would look like without it.
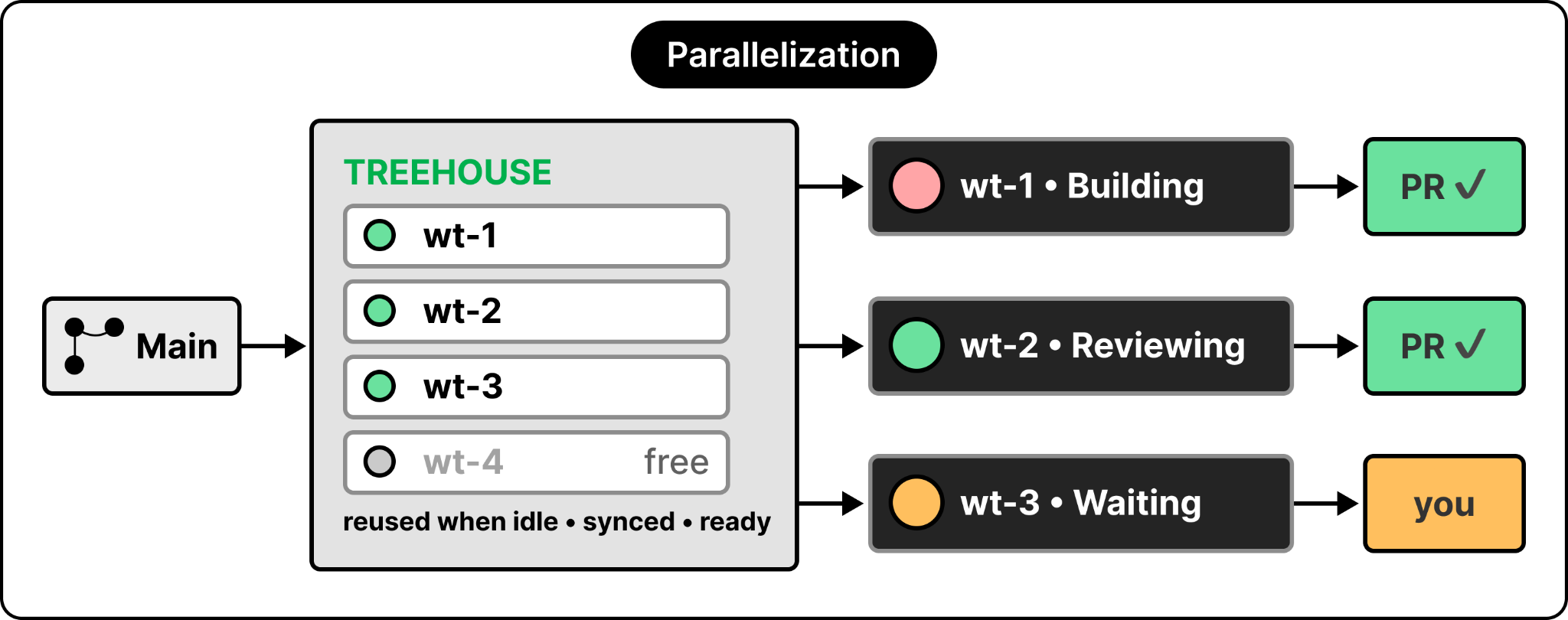
With a fully autonomous implement-and-validate pipeline, a single task can take a while, and that’s a good thing, because it frees me up to run more things at once.
In tmux, this means opening a new window. Terminal tabs achieve the same parallelism. The important part is keeping those tabs visible and showing each agent’s status in the tab title. Claude Code and Codex do this out of the box; for harnesses that don’t, I wrote small plugins to do the same, and I made the no-mistakes tool report its status as a custom title too.
That one detail is what lets me run many sessions without going insane. At any moment, I can see which agents are running, which are done, and which need my input. A couple of tmux keystrokes jump me to any tab.
The other problem with running agents in parallel is that they step on each other’s toes when they share a directory.
Git worktrees exist to solve this. A worktree is an efficient clone of the same repo in another directory where you can work in parallel. But worktrees carry a lot of cognitive load: where to put them, how to name them, create a new one or reuse an old one, which are in use, which have dependencies installed, and whether env files are ready. What I actually want to think about is the work, not where to do it.
So I built another open-source tool named treehouse. You’re in a repo, you want to start a parallel task, you run treehouse, and it drops you into a ready worktree. Behind the scenes, it manages a pool of worktrees, tracks which are free, reuses an idle one when possible (so dependencies, build artifacts, and env files are already there), and makes sure it’s synced with the latest main before dropping you in. I don’t think about any of that. I simply run the treehouse tool and start working.
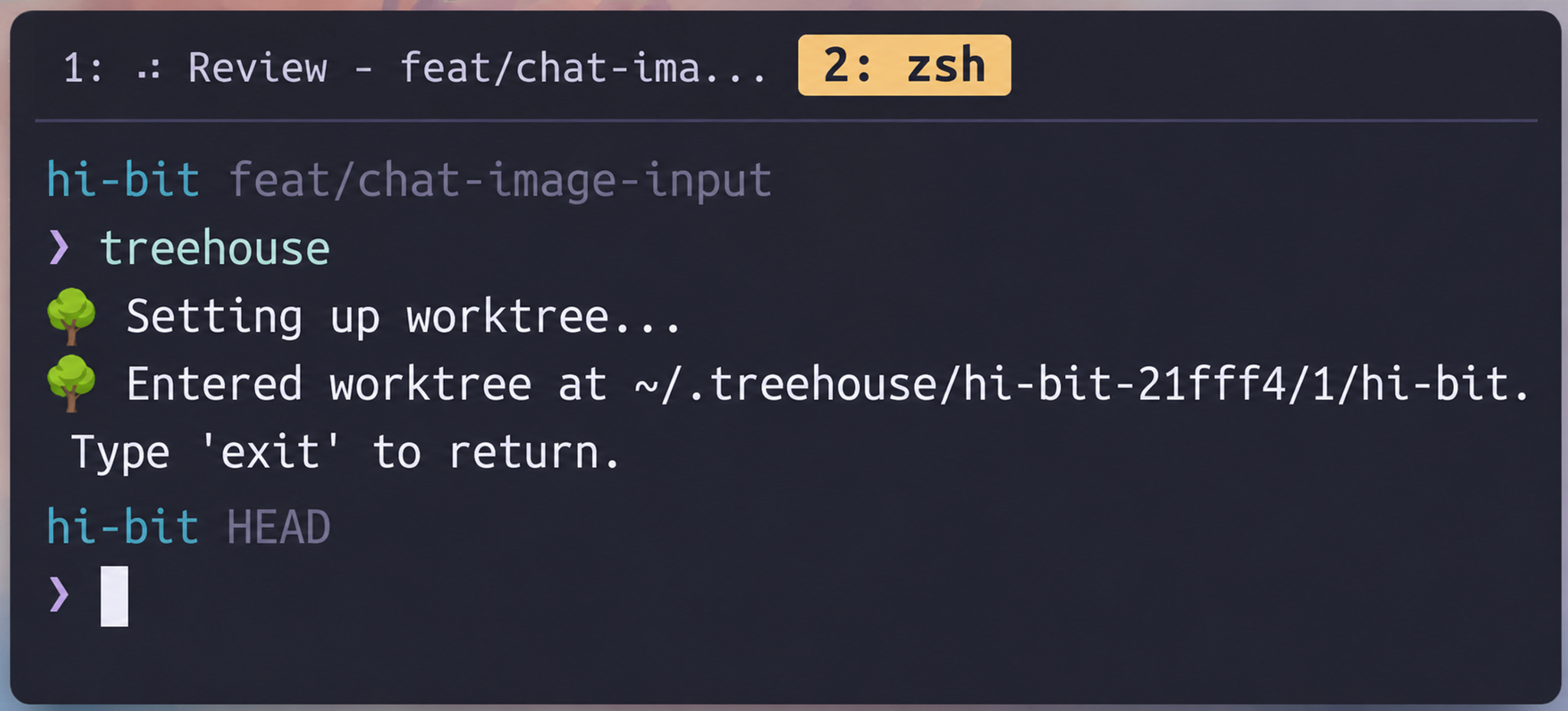
I repeat this and usually end up managing 5 to 10 tasks at once. I don’t context-switch much because most of them go straight to a clean PR with no involvement from me. Occasionally, the no-mistakes tool escalates something for a decision, but most of the time, I’m just thinking about and writing the next instruction.
The diagram below tries to show the parallelization angle that I’m talking about:
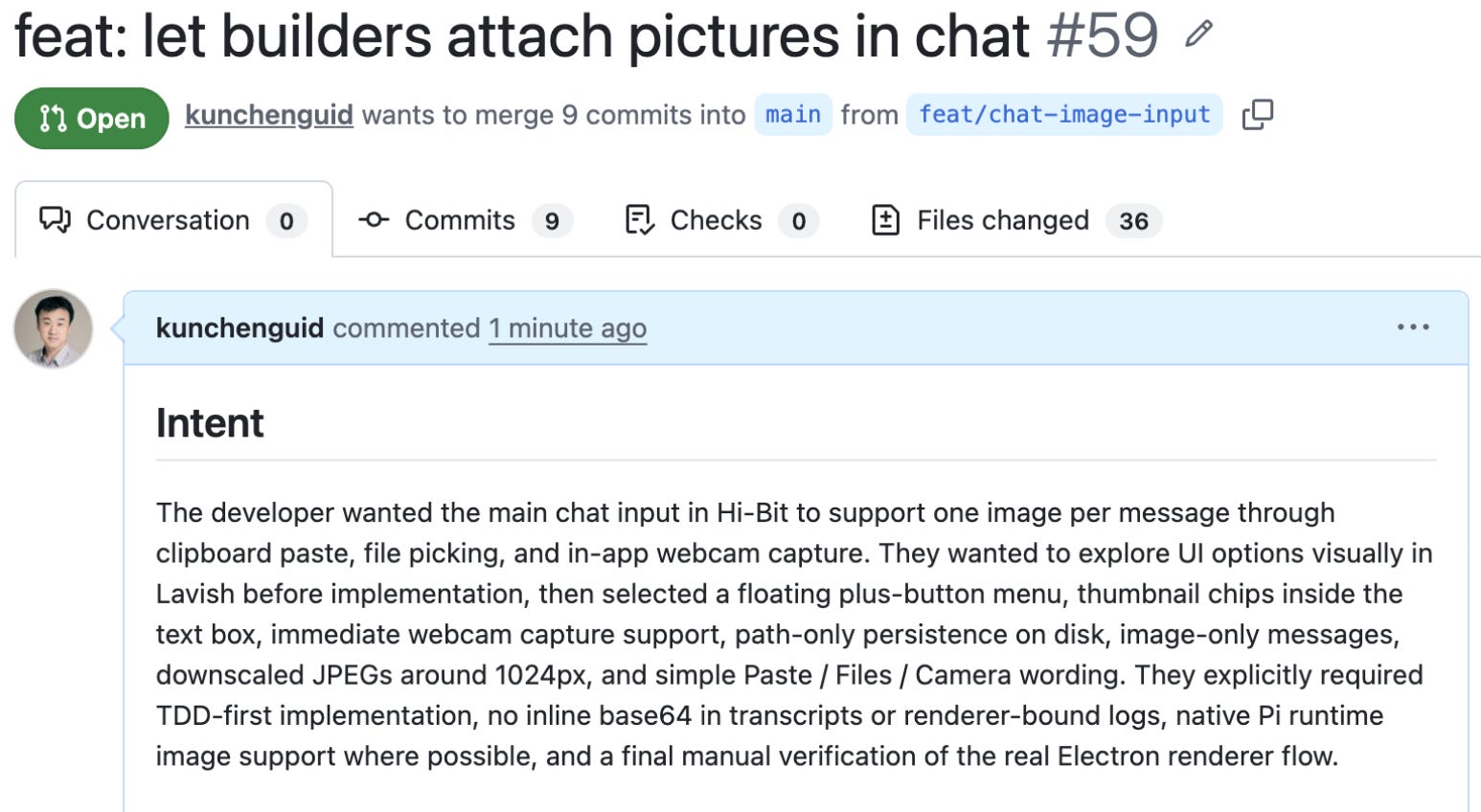
A little while later, the image-attachment task’s pipeline finished and handed me a PR that was ready to merge. Many issues had been caught and auto-fixed along the way, all logged on the PR, so I can audit them. Also, my favorite part, a “Testing” section with evidence (including screenshots) that the feature works end-to-end, is presented.
Every couple of weeks, I have to drive my son to a birthday party, where I’d find myself useless for a few hours. He’d be having a great time with his friends while I sat somewhere with no Wi-Fi, missing my agents and wondering whether they were blocked and waiting on me.
That stopped once I set up the remote control feature. I don’t use the built-in remote features from Claude Code or Codex for a few reasons:
-
I want one consistent workflow across all my agents, not separate apps that do the same thing but stay siloed because different companies want to lock me in.
-
I want real, full terminal access — not an agent-only view — so I can also run treehouse, no-mistakes, and gnhf.
-
I want perfect continuity across phone, laptop, and PC. My son has zero patience: if he says it’s time to leave, I get up and go. If I typed half a sentence on my phone, I want to finish it on my PC later.
So I set up Tailscale, which puts my PC, laptop, and phone on the same private network where they can reach each other safely. I then ssh between them (which on Mac just means enabling “Remote Login”). On my phone, I use an SSH client to connect to my Mac, attach to my tmux session, and instantly I’m in the same workspace with the same tabs, same agents, same environment.
To keep the connection stable, I use mosh, a transport layer on top of SSH built specifically for terminal state over flaky networks, which matters a lot on cellular. It is the same experience, just more resilient.
So how does all of this come together on a normal day?
-
It usually starts with me talking instead of typing, describing a feature or a gnarly refactor by voice.
-
If it’s complex, I have the agent draft a plan in Lavish Editor and iterate on it in the browser until it’s right.
-
Once the plan is solid, I either ask the agent to implement it directly or hand it to gnhf if it’s big, while I spin up a fresh worktree with treehouse and start the next task in a parallel tmux window.
-
When an agent finishes, I don’t read massive diffs line by line. I run no-mistakes, which reviews the code, tests it end-to-end, and opens a clean PR while I move on.
-
When I’m away from my Mac, I SSH in from my phone, and the whole workspace stays with me.
Here’s what the workflow looks like on a high level:
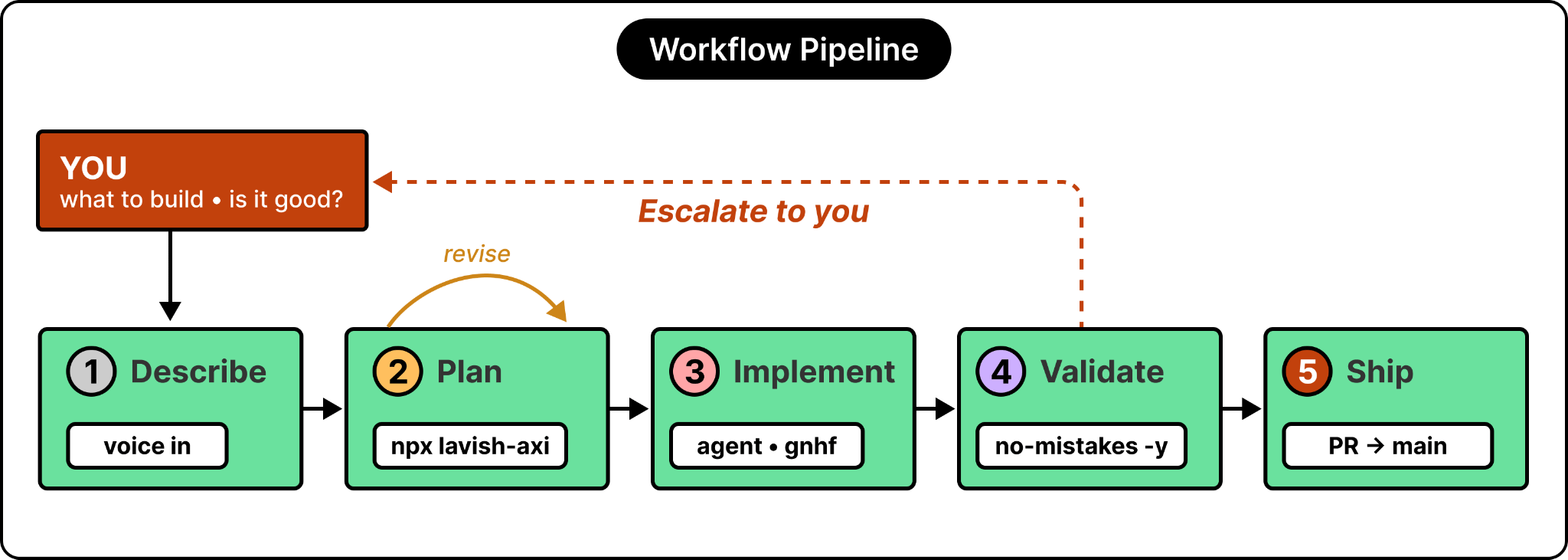
Each tool removes one specific point of friction, and together they chain into a smooth workflow I genuinely enjoy. I get to stay at the level of deciding what to build and whether it’s good, while most of what’s in between runs itself.
That’s everything I can think of that made a meaningful difference in my workflow. Reflecting on how it came together over the past couple of years, my biggest realization is that as the models keep advancing, the tooling and workflow around them will keep evolving too. What works well today may be obsolete a few months from now.
At the same time, relying only on off-the-shelf products like Claude Code and Codex is never quite enough. There’s always room for a better, more efficient workflow to take the agents a step further. I benefited a lot from building custom tools to remove whatever friction I hit. You’ll likely face a different set of problems because you work on different projects with different processes.
So I’d encourage you to never accept anything that slows you down. If part of your workflow frustrates you, chances are others are hitting the same thing. Find a tool that fixes it, or build one and share it. We’re in the middle of an industrial revolution. It’s the best time to be creative and redefine how things should work. Let’s tinker and have fun.



