
Sign-up forms were built for humans in browsers, so how do AI agents programmatically register with services?
Enter auth.md. By exposing a single, machine-readable Markdown file at your service root, AI agents can dynamically discover your OAuth Protected Resource Metadata, parse required scopes, and authenticate seamlessly.
With native support in WorkOS AuthKit, you can now implement this protocol out of the box, giving AI tools a standardized, secure way to log into your application.
Everyone is building agents. Most of them will fail at scale. Not because the technology doesn’t work, but because teams don’t know what happens after the demo.
That’s the lesson from Salesforce, which has over 20,000 enterprise customers running Agentforce in production. Their support agent alone has handled over three million conversations.
We sat down with John Kucera, Salesforce’s CPO of Agentforce, to learn what separates agents that deliver real business value from those that stall after a good demo.
Salesforce is the enterprise software leader, and its Agentic Enterprise Architecture defines how AI agents are built and deployed across business operations.
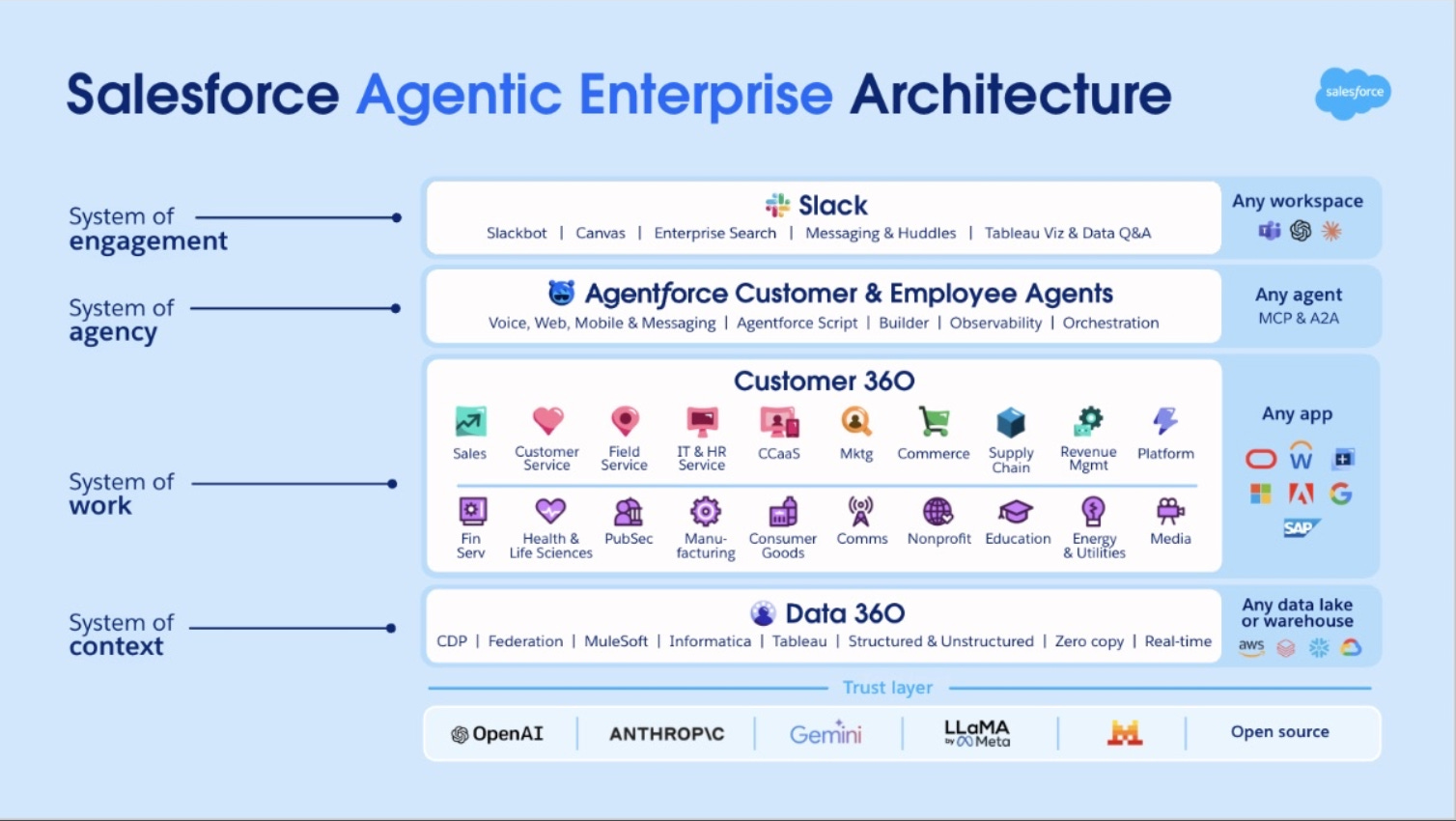
The Agentic Enterprise Architecture has four layers. At the top is the engagement layer, where users interact with agents through their everyday tools like Slack, chat, or messaging apps. Below that is the agent layer, where the AI reasoning and decision-making happens. This is where agents are built, monitored, and orchestrated.
Below the agent layer is the system of work, which incorporates the apps trusted by, and tailored for, your department and your industry. These are the business applications where real work gets done, like resolving a support case, processing a return, or updating a sales pipeline. Lastly, the context layer provides agents with the data and metadata they need to ground their actions in real context, ensuring decisions are informed by the specific business operations.
A trust layer spans the entire stack, supporting multiple LLM providers and enforcing the guardrails we cover later in this article.
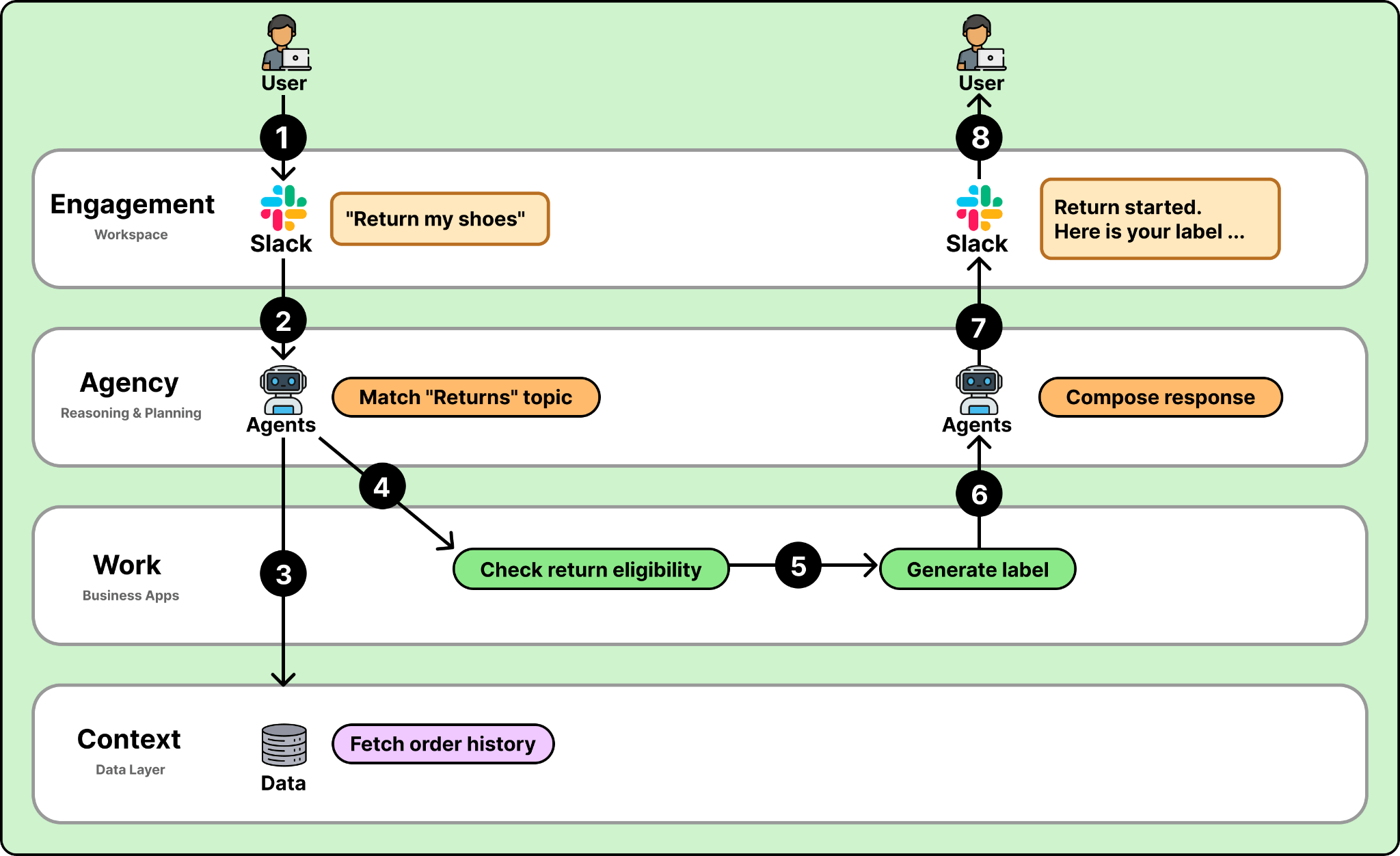
Together, these layers let customers go from idea to working agent without building the infrastructure from scratch. Agentforce provides the reasoning, the data access, the business applications, and the trust controls as a connected platform. But having the right architecture is only part of the story. Once 20,000 customers started deploying agents on this platform, Salesforce discovered something that reshaped how they think about the entire product: the hardest part isn’t building the agent. It’s what happens after you ship it.
What is Agentforce?
Agentforce is Salesforce’s platform for building and deploying AI agents in the enterprise. Rather than a single model or chatbot, it’s a layered architecture designed to embed agentic AI across Salesforce’s entire ecosystem like sales, commerce, and services.
Agentforce elevates every experience by bringing together humans, applications, AI agents, and data. Now any company can safely deploy agents that work for their customers, suppliers, and employees 24/7. Teams can manage the complete agent development lifecycle with a robust set of tools to build, test, deploy, manage, and orchestrate AI agents at scale.
Agents built on LLMs are flexible by design. They can interpret a wide range of inputs and decide what to do in real time. But that flexibility comes with a tradeoff. Because LLMs are non-deterministic, the same question can produce different steps each time. Across Salesforce’s deployments, this was one of the most common challenges: keeping agent behavior consistent and reliable, especially in high-stakes workflows.
The reason this is so hard comes down to how AI agents differ from traditional software. In traditional software, the effort distribution looks roughly like this:
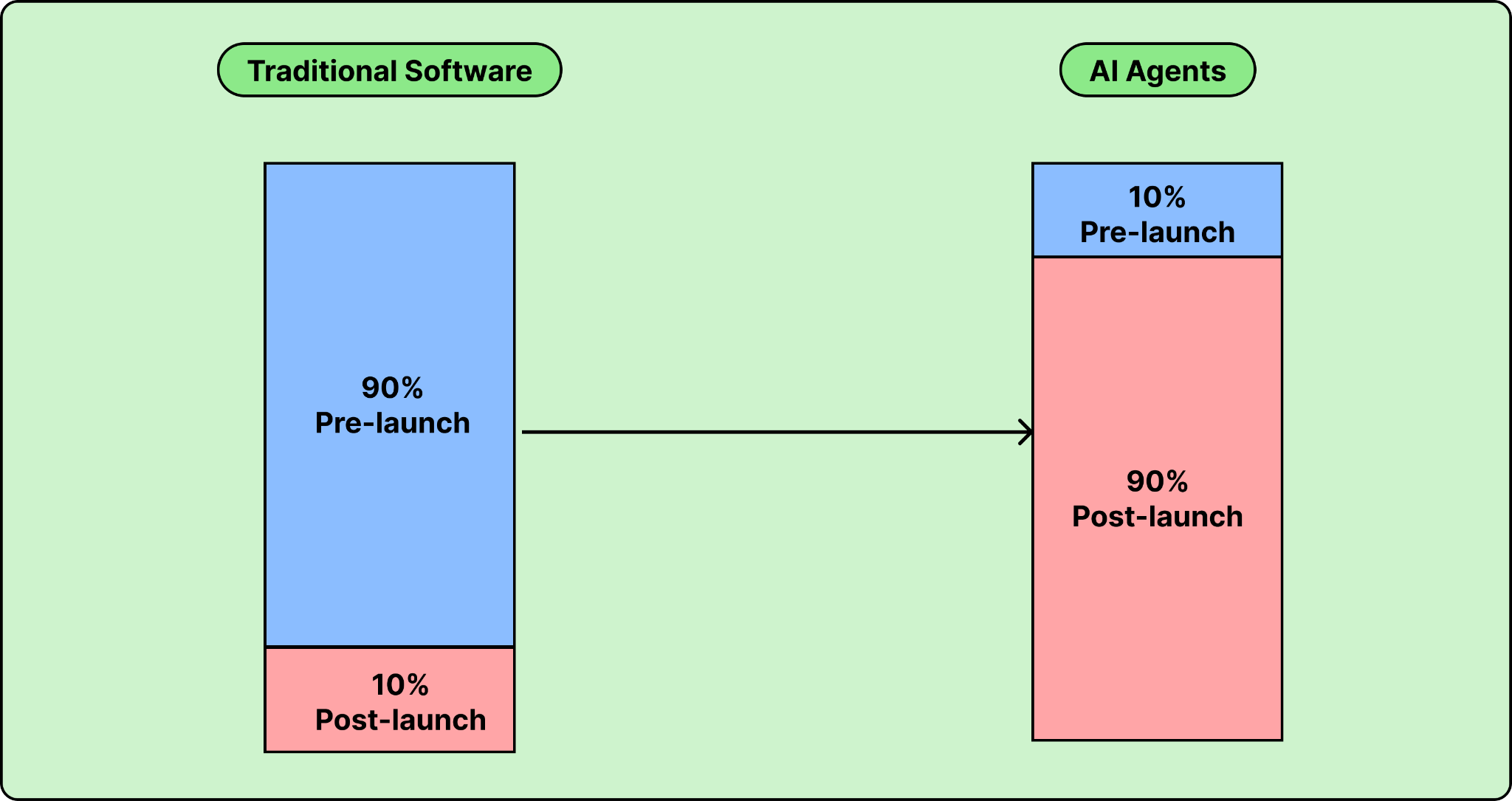
With traditional software, 90% of the work happens before launch. You gather requirements, design the architecture, build it, and test it. After launch, you’re mostly in maintenance mode. With AI agents, this ratio flips. As Kucera put it: “In the typical software world, 90% of the work is getting to go live. Whereas in the typical AI agent, 90% of the work is after you go live to manage and improve the agent.”
This is the main reason most enterprise agents fail. Teams follow the traditional software playbook and assume the hard work is done once the agent is live. It’s not. That’s when it starts.
Modern tooling makes this worse. You can build a working agent in an afternoon. The demo handles the typical questions well. Leadership sees it and greenlights production. But typical questions are only a minority of what real users will ask. The majority involves edge cases, ambiguous phrasing, and cross-domain questions. That’s where the agent earns or loses trust.
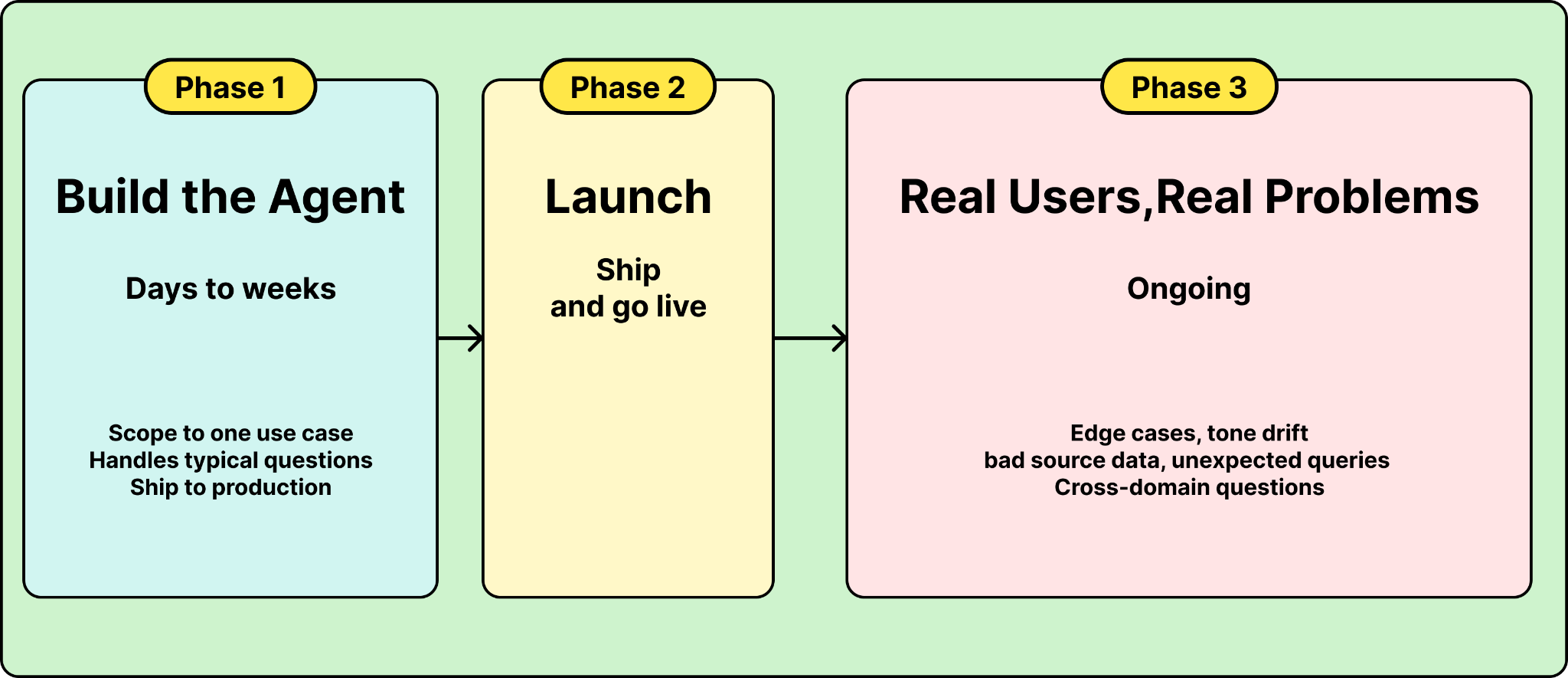
The teams that succeed treat launch as the starting line. That means two things: 1) get the pre-launch foundations right so they can iterate on quickly, and 2) budget the majority of effort for post-launch and continuous improvement.
These production realities forced Salesforce to evolve Agentforce itself. Models are inherently probabilistic, predicting the next best response rather than executing fixed logic. That makes them powerful for reasoning and natural interaction, but enterprises still need deterministic systems underneath for consistency and trust. The future of enterprise AI is the combination of both: deterministic workflows set the guardrails, while probabilistic AI adds adaptability and contextual reasoning on top. Features like Agent Script and Hybrid Reasoning are the direct result of watching 20,000 deployments hit this wall. The rest of this article covers the pre-launch and post-launch lessons that shaped that evolution.
If 90% of the work is post-launch, then the goal of pre-launch isn’t to build the perfect agent. It’s to build an agent you can effectively iterate on. That means choosing the right scope, defining how you’ll measure success, and putting the trust, security, and safety guardrails in place from the start.
Kucera put it simply: “Don’t boil the ocean.” When building your agent, it’s tempting to go after something ambitious. Don’t. Pick a use case that is both high-value and achievable. There are two reasons for this.
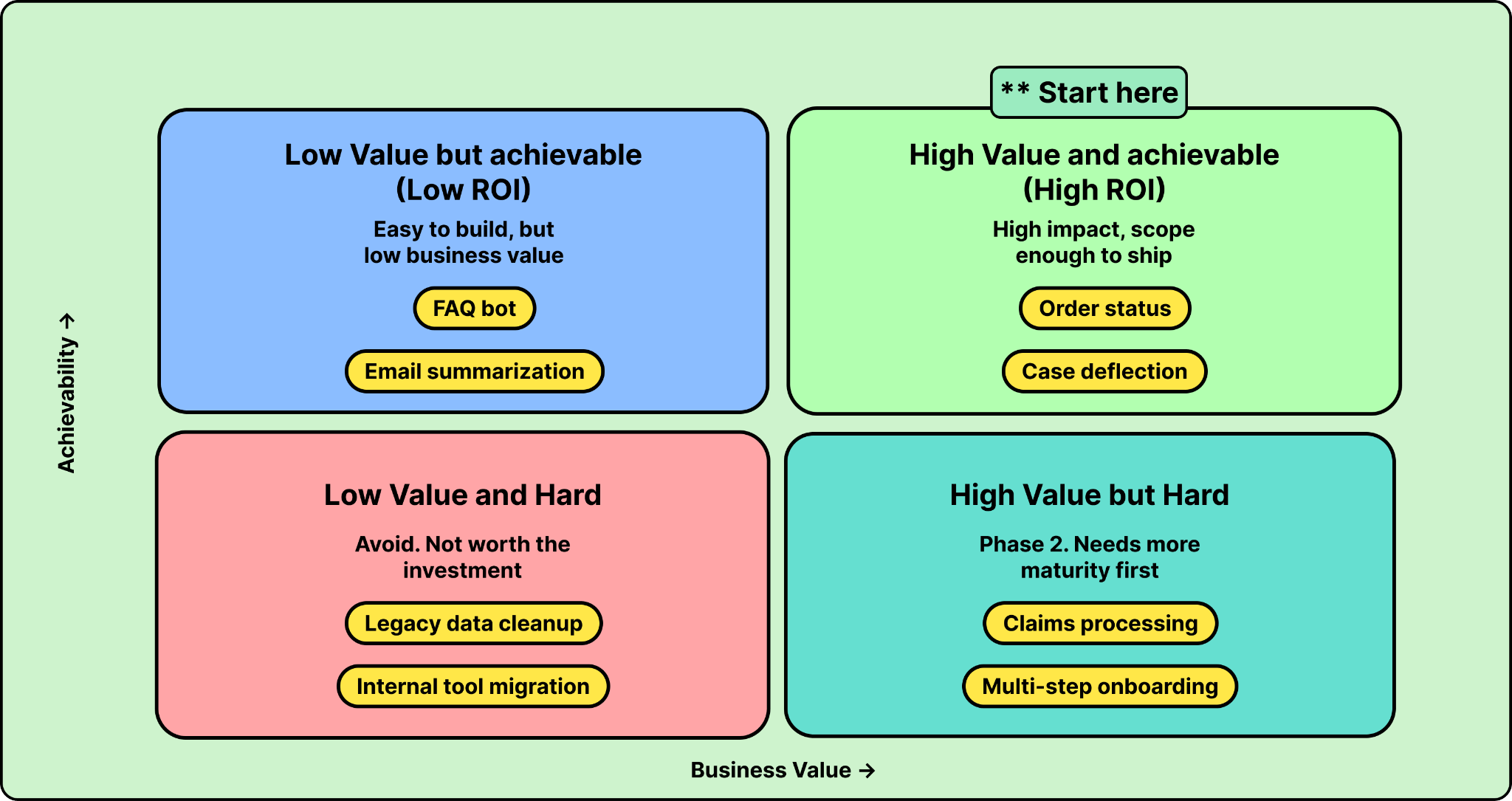
First, agent capabilities are still evolving fast. What’s possible today will look different in six months. If you invest heavily in a complex, multi-step agent now, you may end up rebuilding it as better models and tooling arrive. A focused use case gives you real production learnings without overcommitting to today’s limitations.
Second, the process of building agents is different from traditional software. Your team needs to learn how to review agent transcripts, figure out why the agent made a wrong decision, and update instructions, tools, and data sources. That learning is faster and lower-risk when the use case is small.
Starting small pays off soon. Once your team has shipped one agent, measured its impact, and learned the iteration cycle, scaling to the next use case is much faster. But even a focused agent needs a clear definition of success.
A common failure pattern across Salesforce’s customer base is that teams push an agent to production without defining what success actually means. Without a measurable goal, there’s no way to know if the agent is working or drifting.
This is where Agentic Work Units (AWUs) become critical. Introduced by Salesforce, AWUs are discrete units of meaningful work completed by an agent and provide a standardized way to measure actual task completion. They give teams a consistent framework to quantify value beyond activity or interactions, focusing instead on whether the agent is truly getting work done.

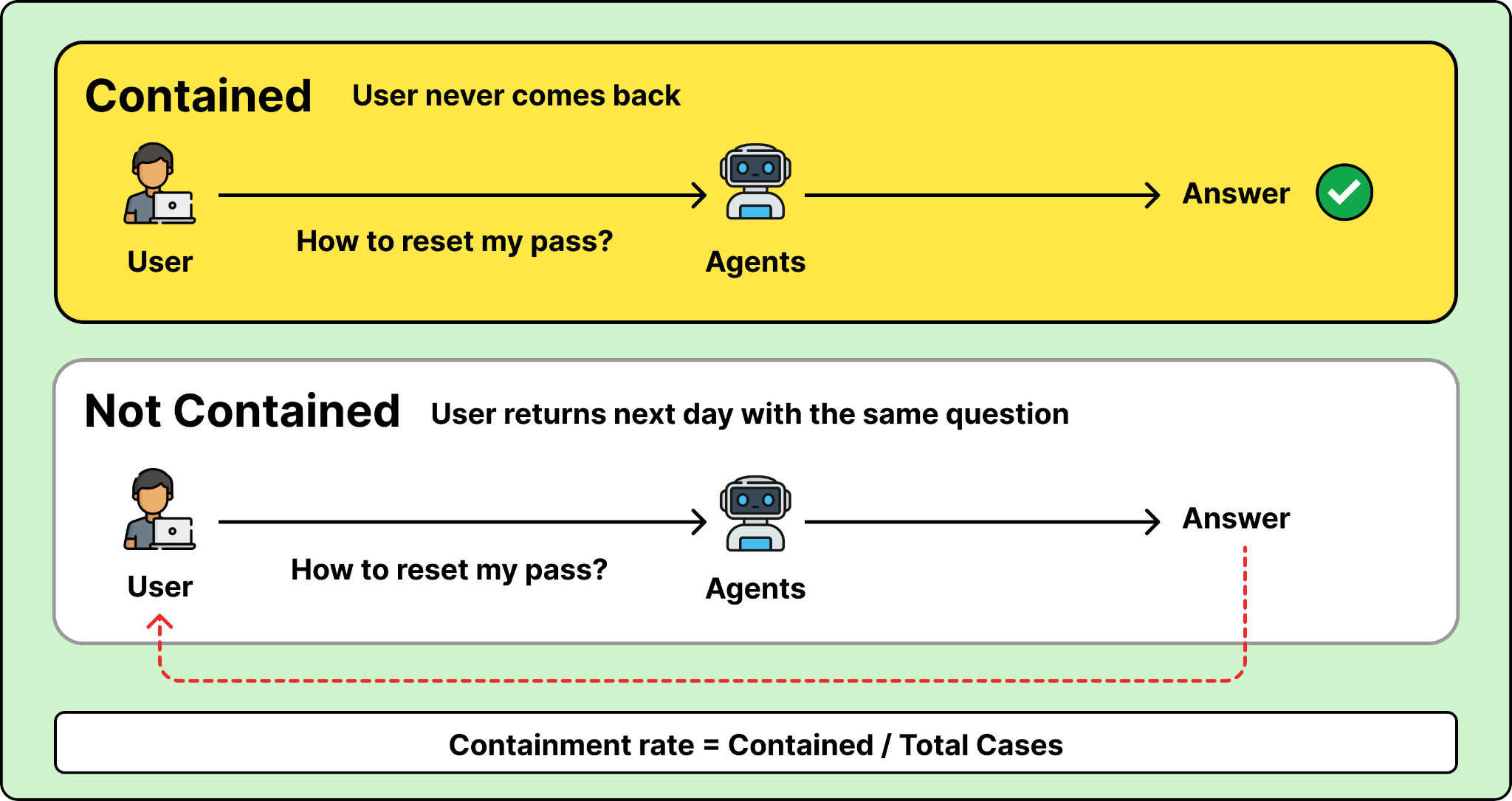
Every agent needs a concrete KPI tied to a real business outcome. For Salesforce’s own support agent at help.salesforce.com, that KPI is containment rate.
Containment rate means the percentage of cases fully resolved by the agent without human follow-up. A user asks “How do I reset my password?” The agent gives a clear answer, the user solves their problem, and never comes back for the same issue. That’s contained. But if the user returns the next day asking the same thing, the agent failed to actually help.
AWUs complement this by turning those outcomes into a consistent measurement of work completed, how many user intents were fully resolved per interaction, allowing teams to track not just whether a case was contained, but how efficiently and reliably the agent is performing work at scale.
The KPI also drives your post-launch iteration. When your team reviews transcripts and decides what to fix next, the KPI tells you what matters. A tone issue might be annoying, but a logic error that tanks your containment rate gets fixed first. Over time, AWUs become a shared language across product, engineering, and operations for evaluating agent performance, complementing traditional KPIs like containment rate with a more granular view of agent productivity.
With scope and KPIs in place, the last pre-launch foundation is the trust layer.
Your agent sits between your users and your data, with an LLM in the middle. Data flows in both directions: user queries pull sensitive data into the LLM’s context, and the LLM’s responses flow back to users, sometimes triggering real actions. Each direction creates different risks, from data privacy leaks on the way in to hallucinated actions on the way out.
In practice, teams implement two guardrails on both sides of the LLM. Input guardrails to protect data before it reaches the LLM, and output guardrails to validate the LLM’s response before it reaches the user.
When your agent needs data to answer a question, that data has to travel from your systems into the LLM prompt. This is where things can leak. The core protections are secure data retrieval, zero data retention, and keeping data inside a trusted boundary. Data masking is also available, but as we’ll see, it comes with a tradeoff that makes it the wrong default for most agents.
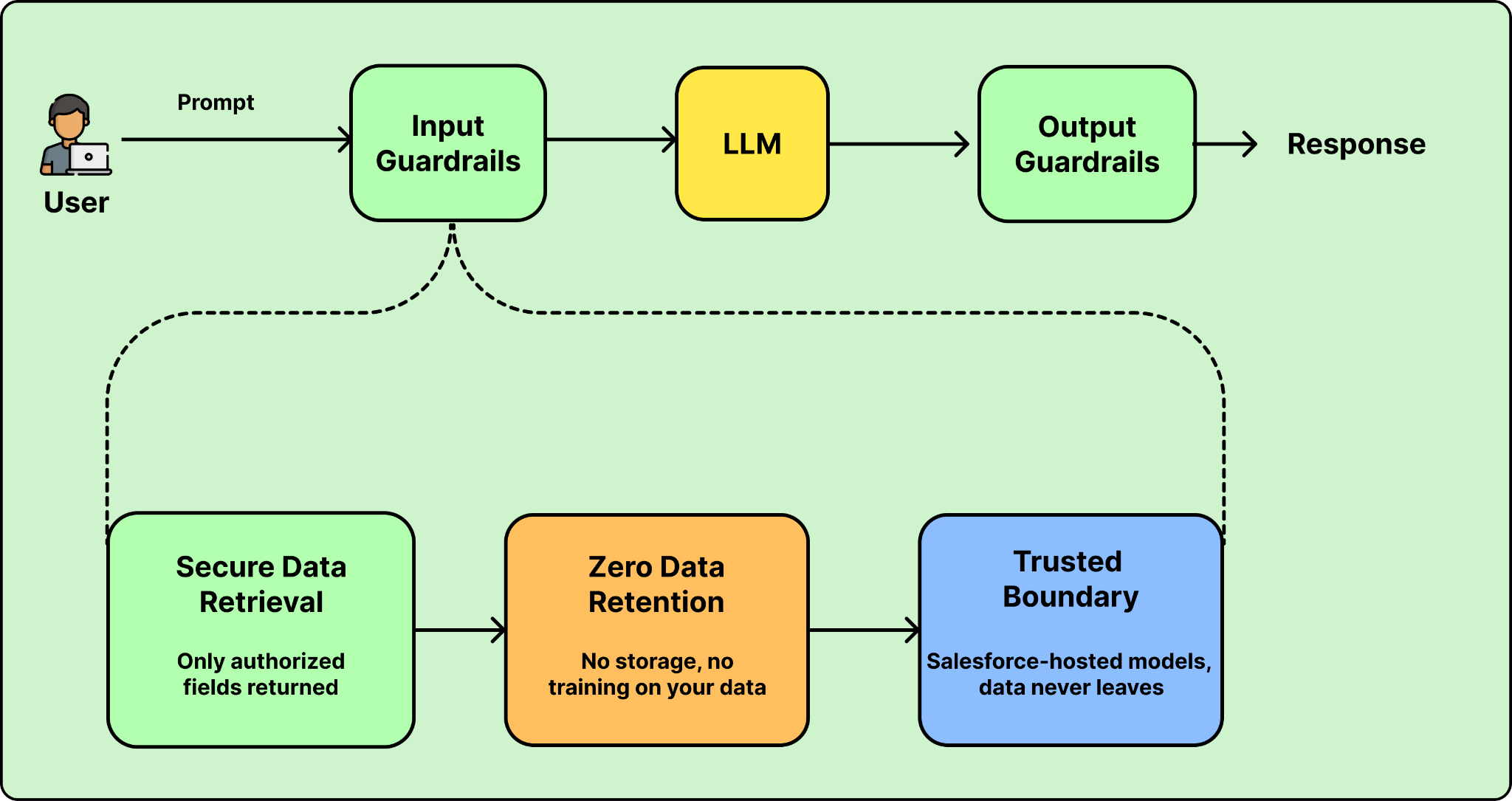
Secure data retrieval means you control exactly how data enters the prompt. Instead of giving the LLM raw access to a database, you route requests through a controlled layer that only returns what the agent is allowed to see.
Zero data retention is an agreement with your LLM provider that they won’t store your prompts or responses, and won’t use them to train future models. Anything sent to an external LLM is covered by this contract: it isn’t retained, viewed, or used for training once the response is returned. Without it, your customer data could end up embedded in a model that serves other companies.
Keeping data inside a trusted boundary goes one step further. For the most sensitive workloads, you can route requests to a provider-hosted model that sits inside your platform’s trust boundary, so the data never crosses the public internet at all. On Agentforce, for example, custom actions can call Salesforce-managed models like Anthropic’s Claude hosted within the Salesforce trust boundary. The data stays inside the boundary, and zero data retention still applies.
Data masking is the one input guardrail to use with care. It catches sensitive data before it reaches the LLM, for example detecting a social security number and replacing it with a placeholder token. The catch is that masking can strip out the very context the agent needs. If a user asks the agent to build a list of accounts similar to a reference account, but the reference account’s details are masked, the agent no longer has the information to find the match. For this reason, Agentforce keeps pattern-based and field-based masking off by default for agents, relying on zero data retention and trust-boundary hosting instead. Masking remains a legitimate control where the redacted fields aren’t needed for reasoning, but it shouldn’t be the default for agents that depend on rich context.
Input guardrails protect data on the way in, but the LLM can still produce bad output. Before a response reaches the user, you need a second set of checks such as tool validation, grounding checks, and content filtering.
Tool and sub-agent validation ensures the agent isn’t hallucinating actions, not just text. If the agent decides to route to a “refund_processor” sub-agent that was never defined, the system should catch that and block it.
Grounding checks verify the agent isn’t making up facts from its general training data. If your agent is supposed to answer based on your help docs, the response should only contain information from those docs.
Content filtering catches harmful or inappropriate content before the user sees it. This includes toxicity scoring and other safety classifiers that screen the agent’s output.
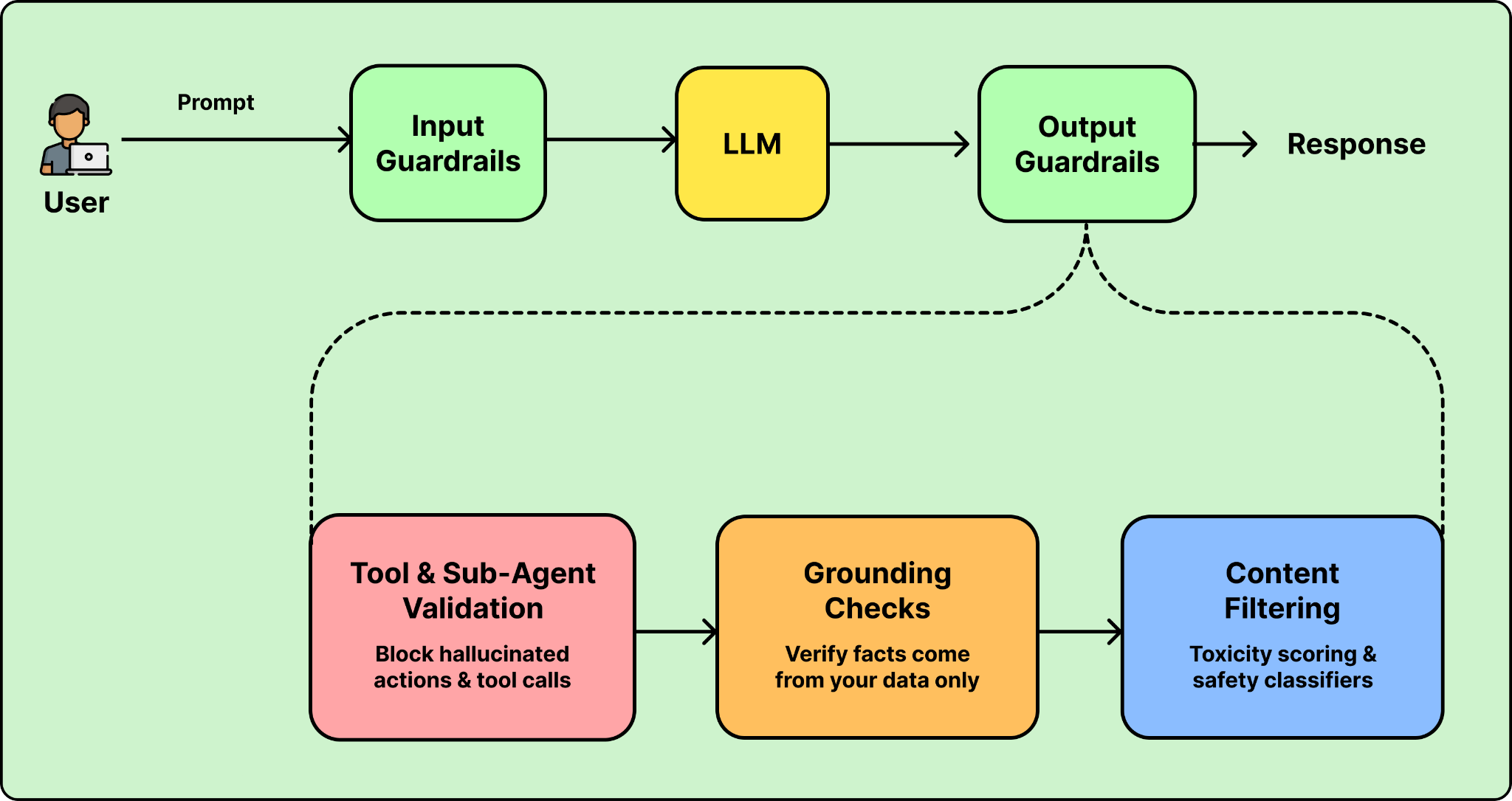
Neither layer alone is enough. PII masking protects your data on the way in but doesn’t prevent hallucinated tool calls on the way out. Output validation catches bad responses but doesn’t stop sensitive data from reaching the LLM. Teams implement both of these layers in practice.
You’ve scoped your use case, defined a KPI, and built your trust layer. The agent is live. As we discussed earlier, this is where 90% of the real work begins. The following lessons come from Salesforce’s experience managing 20,000 enterprise agent deployments once they meet real users.
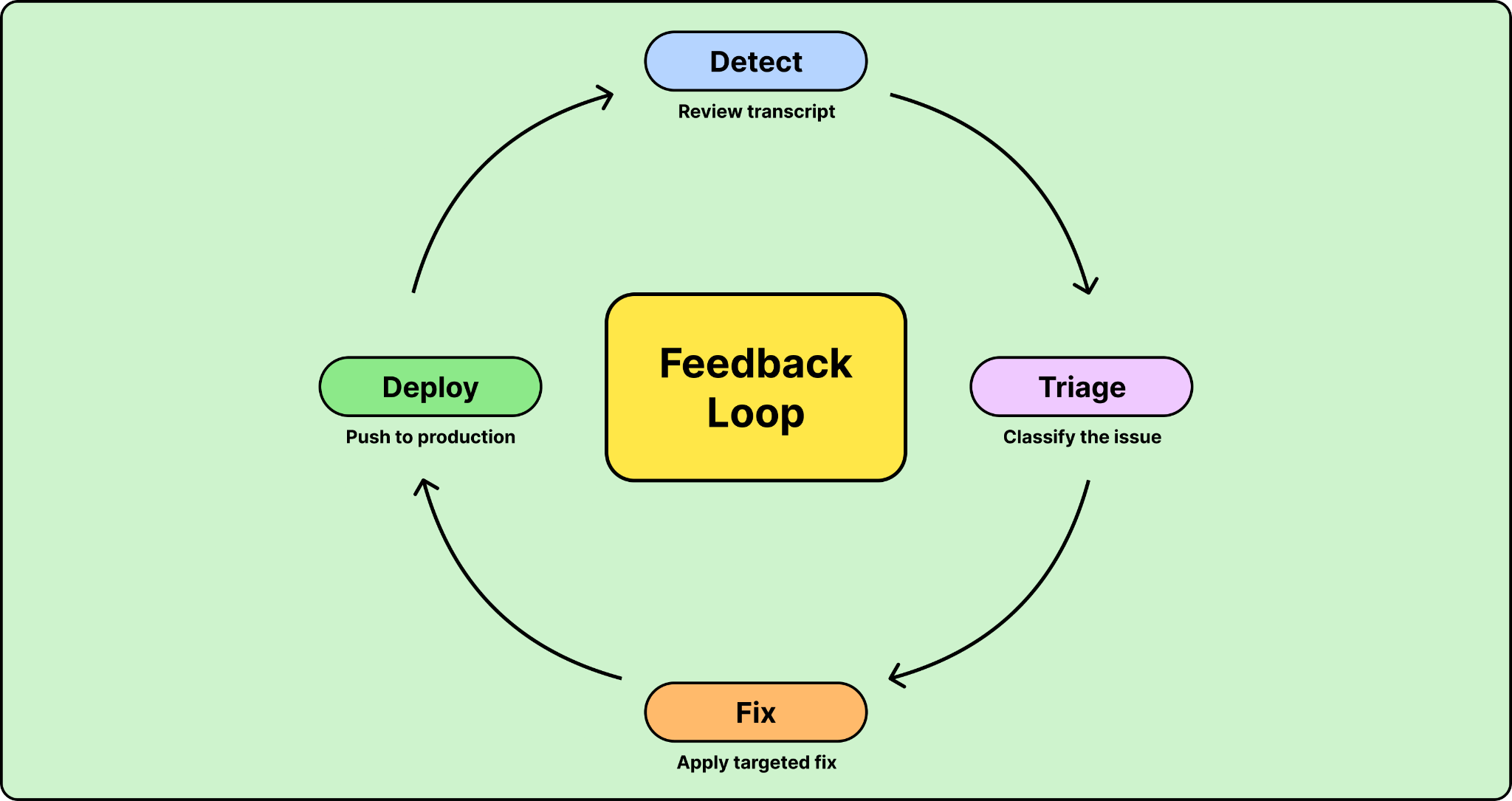
In traditional software, testing is fairly binary. You have unit tests, integration tests, maybe some latency benchmarks. They pass or they don’t. With agents, the failure modes are fuzzier. Users ask things you didn’t anticipate. The agent’s tone drifts from your brand. A retrieved document turns out to be outdated. The agent gets the right answer from the wrong source. This makes the feedback loop an important post-launch investment.
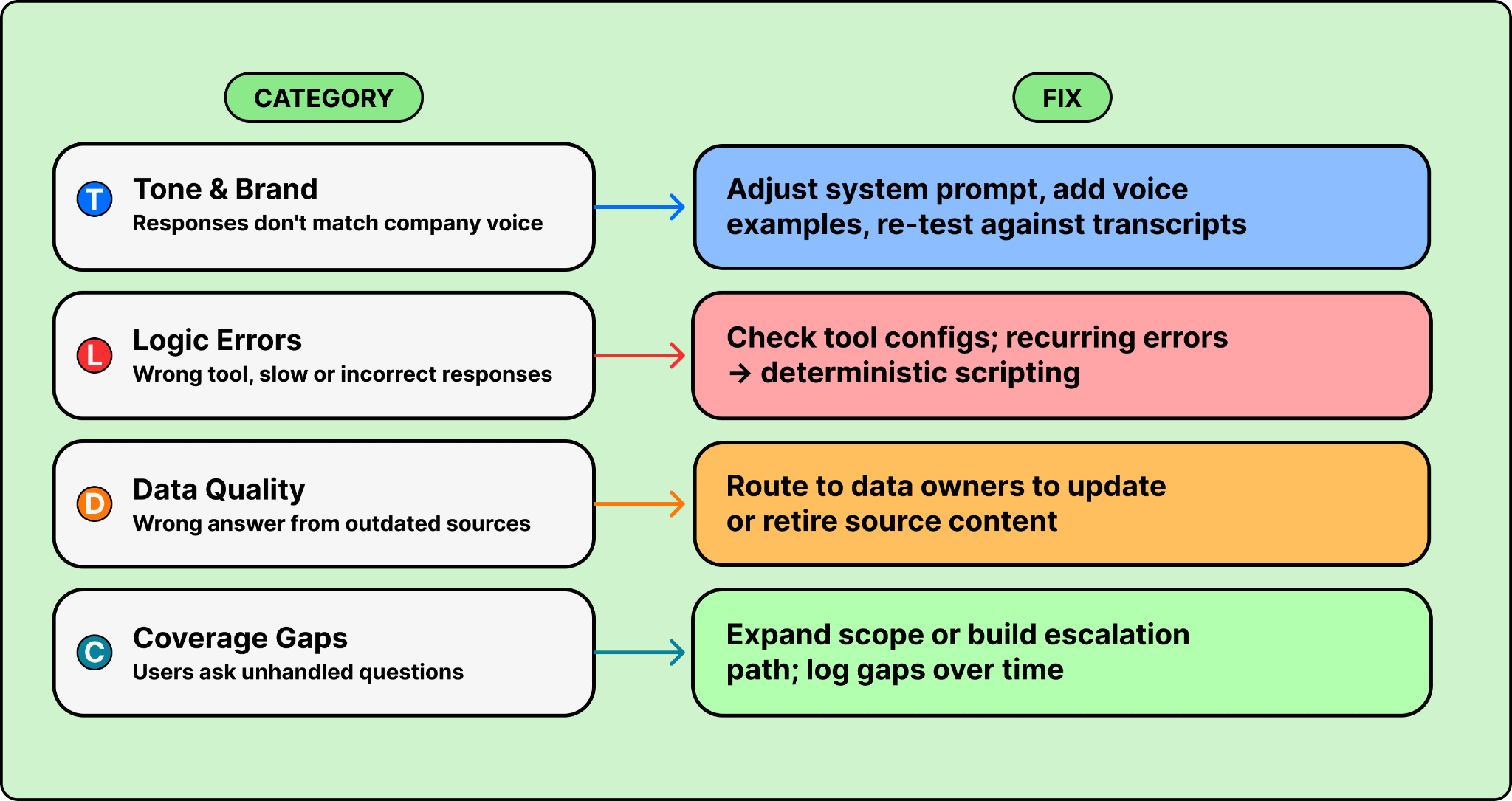
The feedback loop has four triage categories, each with a different fix.
1. Tone and brand alignment. The agent’s responses don’t match your company’s voice. This is especially common with B2C agents where brand consistency matters. The fix is in the system prompt and instructions. Adjust the voice guidelines, add examples of preferred phrasing, and re-test against recent transcripts.
Agibank is one example. Its FAQ agent pulls accurate answers in real time from a knowledge base stored in Agentforce Service, delivering clear responses while staying human, not robotic. “Our principal objective is to reduce effort for customers and provide fast, clear answers through automation, while preserving a welcoming, human tone and not being robotic,” said Akira Vargas Morishita, CX Process & Continuous Improvement Coordinator at Agibank.
2. Logic errors. The agent calls the wrong tool, reasons incorrectly, or takes too many steps to reach an answer. This shows up as slow or wrong responses. Start by checking tool configurations and instructions. If the same error keeps recurring, that flow is a candidate for deterministic scripting instead of LLM reasoning.
3. Data quality. The agent gives a wrong answer not because it hallucinated, but because the source was wrong. Salesforce’s support agent is grounded in 135,000 help articles, and the team regularly finds outdated or conflicting documents behind flagged responses. The fix isn’t in the agent. It’s routing the issue back to the data owners to update or retire the source content.
4. Coverage gaps. Users ask things the agent was never designed to handle. This is inevitable and grows with adoption. The fix is either expanding the agent’s scope or building a clean escalation path to a human. Either way, log the gap so you can track how coverage grows over time.
Telepass is one example. When a question needs human support, such as troubleshooting a device, Agentforce escalates to a live rep with full context so the customer doesn’t have to start over. Before the chat ends, it offers a short survey to capture feedback and satisfaction, and Telepass uses that data to shape its roadmap for future deployments.
The key insight is that this loop needs to be fast. Across Salesforce’s customer base, the speed of this feedback loop turned out to be the gate to scaling. Teams that could quickly triage and fix issues gained confidence in their KPIs and got approval to expand. Teams with slow loops stayed stuck in pilot mode.
The feedback loop catches problems. But some problems are better prevented than triaged. Salesforce identified three recurring anti-patterns that consistently degraded agent performance. Each one is easy to fall into and hard to diagnose through transcripts alone.
The feedback loop catches problems. But some problems are better prevented than triaged. Across 20,000 deployments, Salesforce identified three recurring anti-patterns that consistently degraded agent performance. Each one is a mistake that’s easy to make and shows up in production as degraded accuracy, slow response times, or both.
Not every agent decision needs to go through the LLM. When a customer asks “Where’s my order?”, the correct sequence of API calls is deterministic: look up the order, get its status, get the shipment details. Routing this through the LLM’s reasoning loop means multiple round trips, each adding latency and introducing a chance of error.
This is the most common anti-pattern, and it directly led Salesforce to build Agent Script. Agent Script solves this by letting you define deterministic control flow alongside LLM-powered decision-making. It’s a TypeScript-based scripting framework where you can specify: if the user’s intent matches X, skip the reasoning loop and immediately execute this sequence of tool calls. The LLM is still there for the parts that genuinely need flexibility like understanding ambiguous requests or generating natural language responses, but the predictable parts run as code.
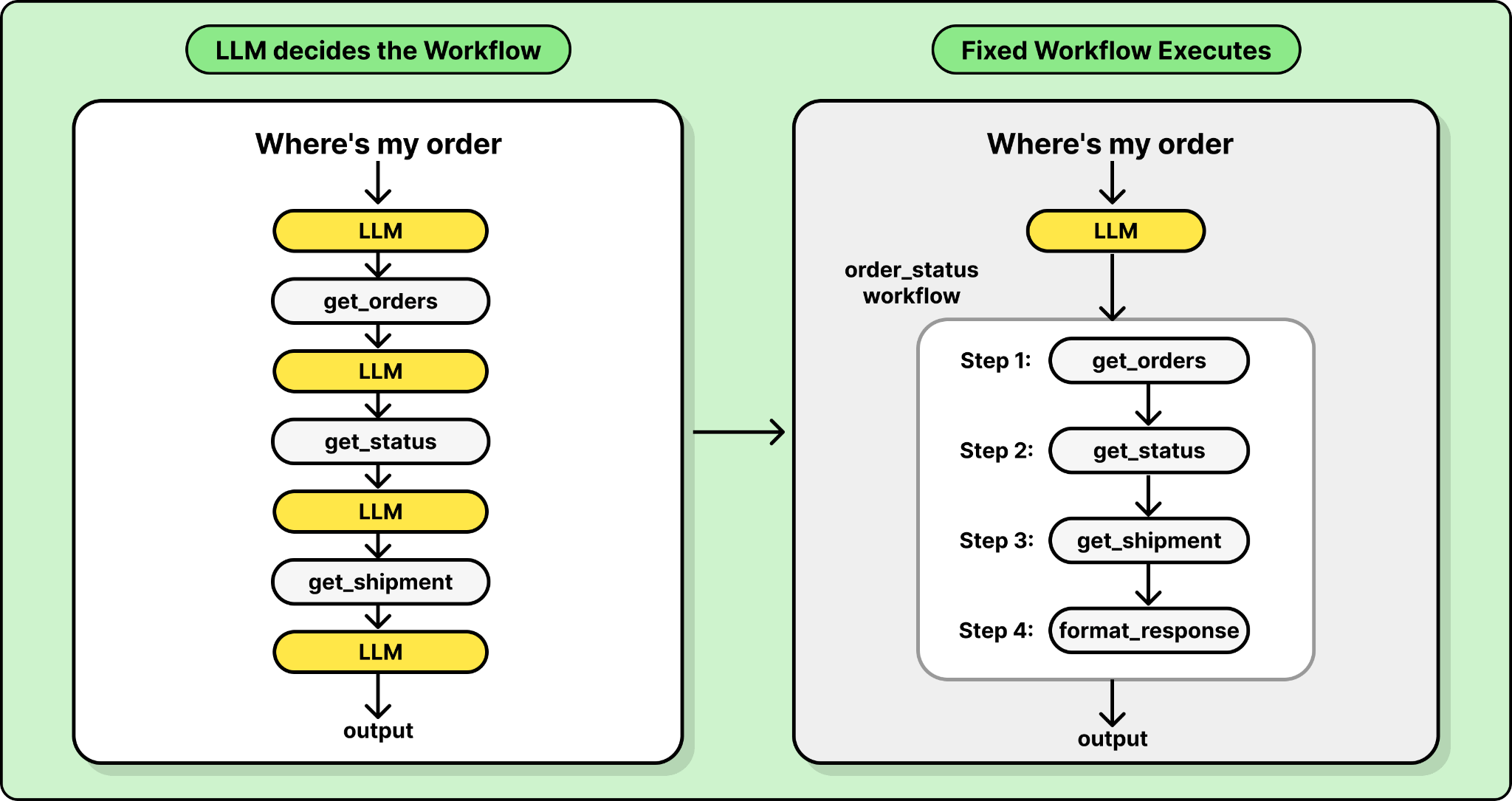
The general principle for developers is that if you can write the logic as a flowchart, it should probably be code, not a prompt.
This one is subtle because it feels like good prompt engineering. Teams discover the agent does something wrong, so they add a strongly worded instruction. “NEVER do X.” “ALWAYS do Y.” They use exclamation points, bold text, and capitalization. When the agent still gets it wrong, they add even more emphasis.
This doesn’t work reliably. LLMs don’t respond to emphasis the way humans do. What works is encoding business rules as explicit, structured policies. For example, if you’re a financial services company that doesn’t operate in Hawaii, you don’t want the LLM to figure that out from a prompt instruction. You need a policy that says: if the customer’s state is Hawaii, return this specific response. No LLM judgment involved.
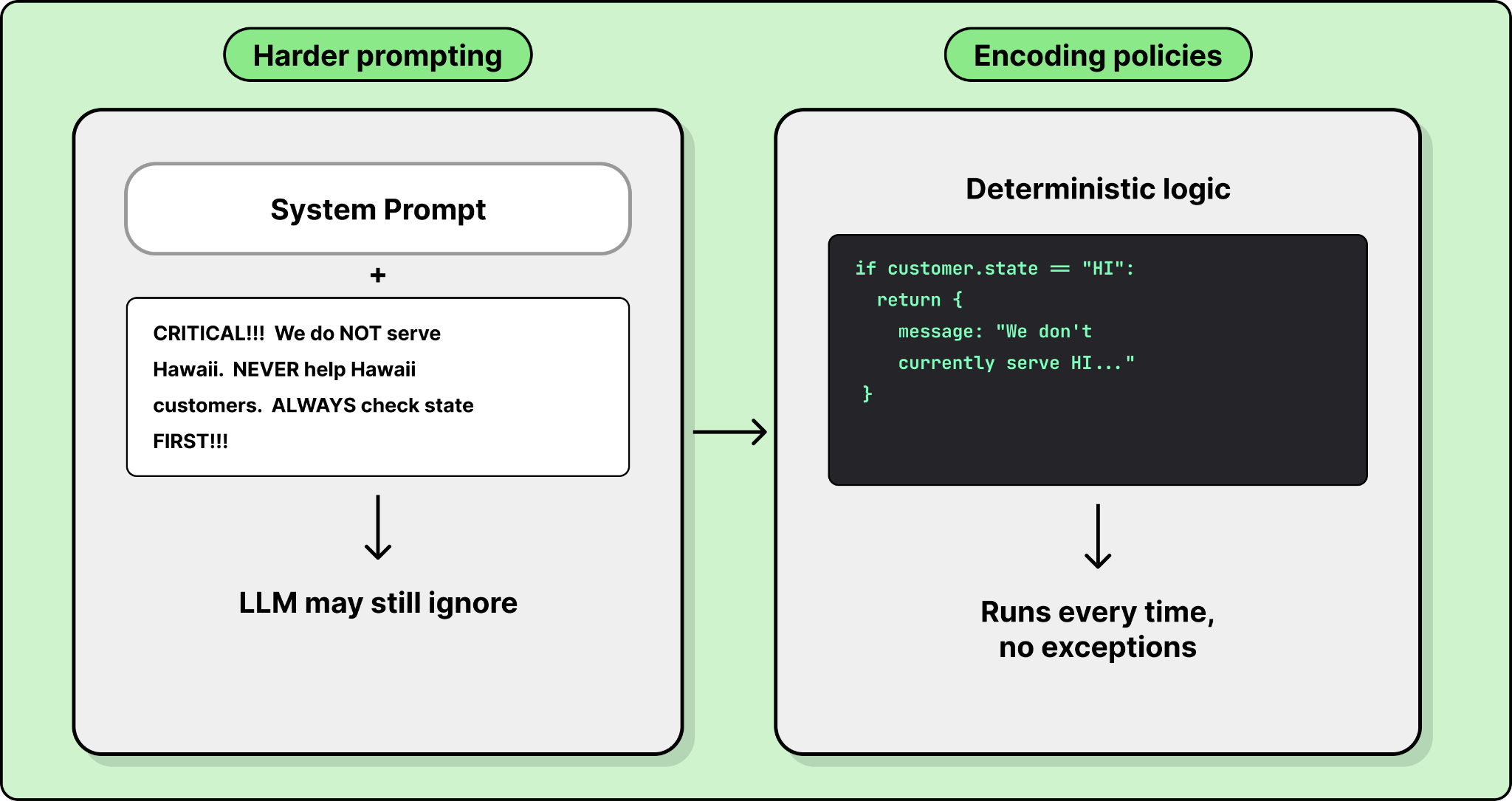
This is another area where deterministic scripting helps. Instead of hoping the LLM internalizes a rule from natural language, you encode it as a conditional in code. It executes the same way every time.
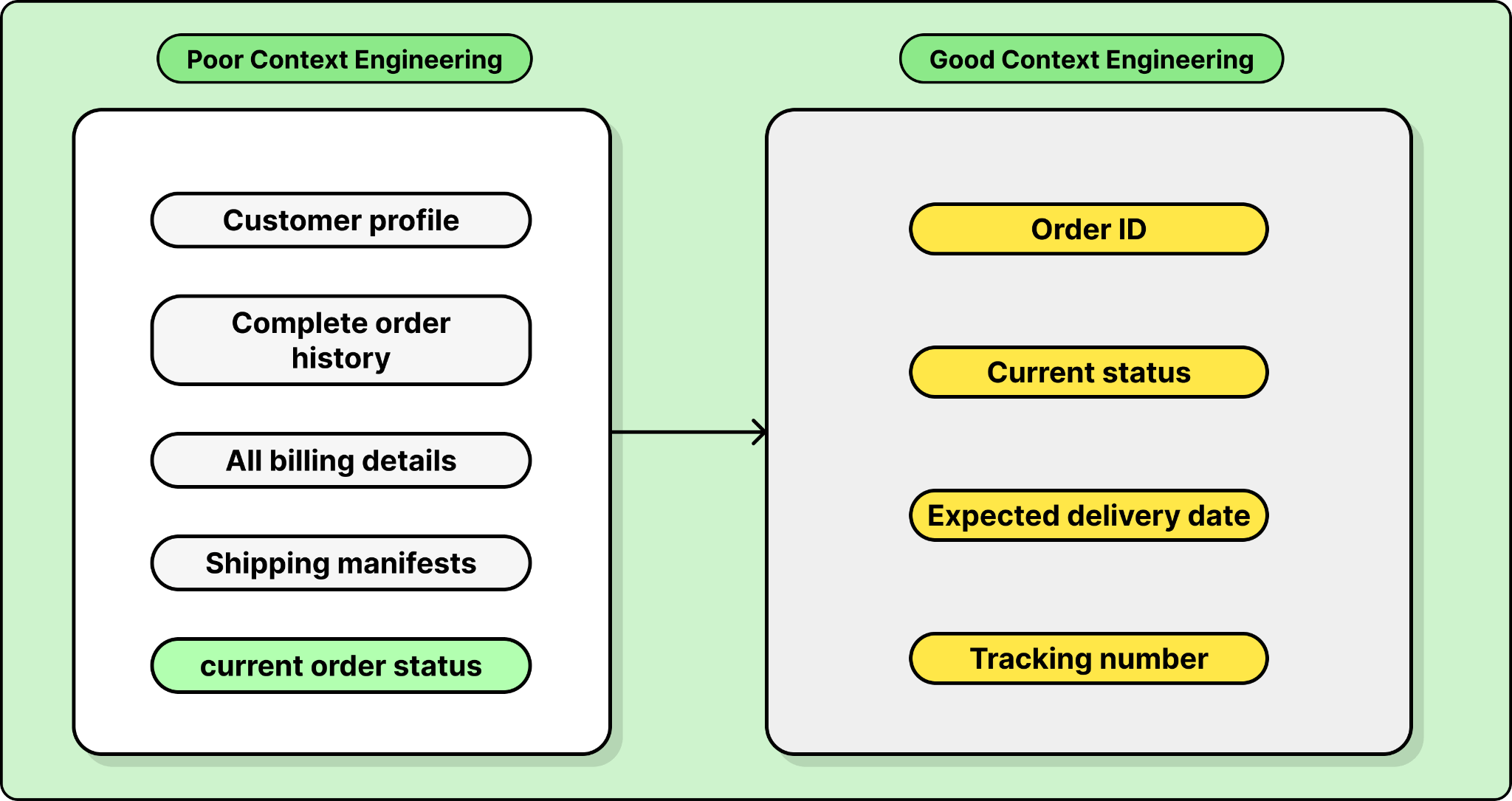
This anti-pattern hurts both accuracy and performance at the same time. Many teams start by passing full, unfiltered API responses into the agent’s context window. A large e-commerce company, for instance, has a get_orders API call that returns roughly 100K tokens by default.
This causes two problems. First, the agent has to reason over a much larger input, which slows response time. Second, the noise makes the agent less accurate. When the relevant information is buried in hundreds of irrelevant fields, the agent is more likely to pick up the wrong data or miss the right answer entirely.
The fix is right-sizing your context. For the e-commerce example, that meant trimming the get_orders response from 100K tokens to roughly 2K by returning only the fields the agent actually needs: order ID, current status, expected delivery date, and tracking number. The same principle applies to document retrieval. One insurance company was loading entire policy documents into context to answer a single question. The fix was retrieving only the relevant sections instead of the full document. In both cases, less context meant faster responses and more accurate answers.
Here are three directions Salesforce sees enterprise agent architecture heading next.
Most agent deployments today use a single agent per use case. The next step is multiple agents working together, where a parent agent coordinates specialized sub-agents, each handling a narrower piece of the problem.
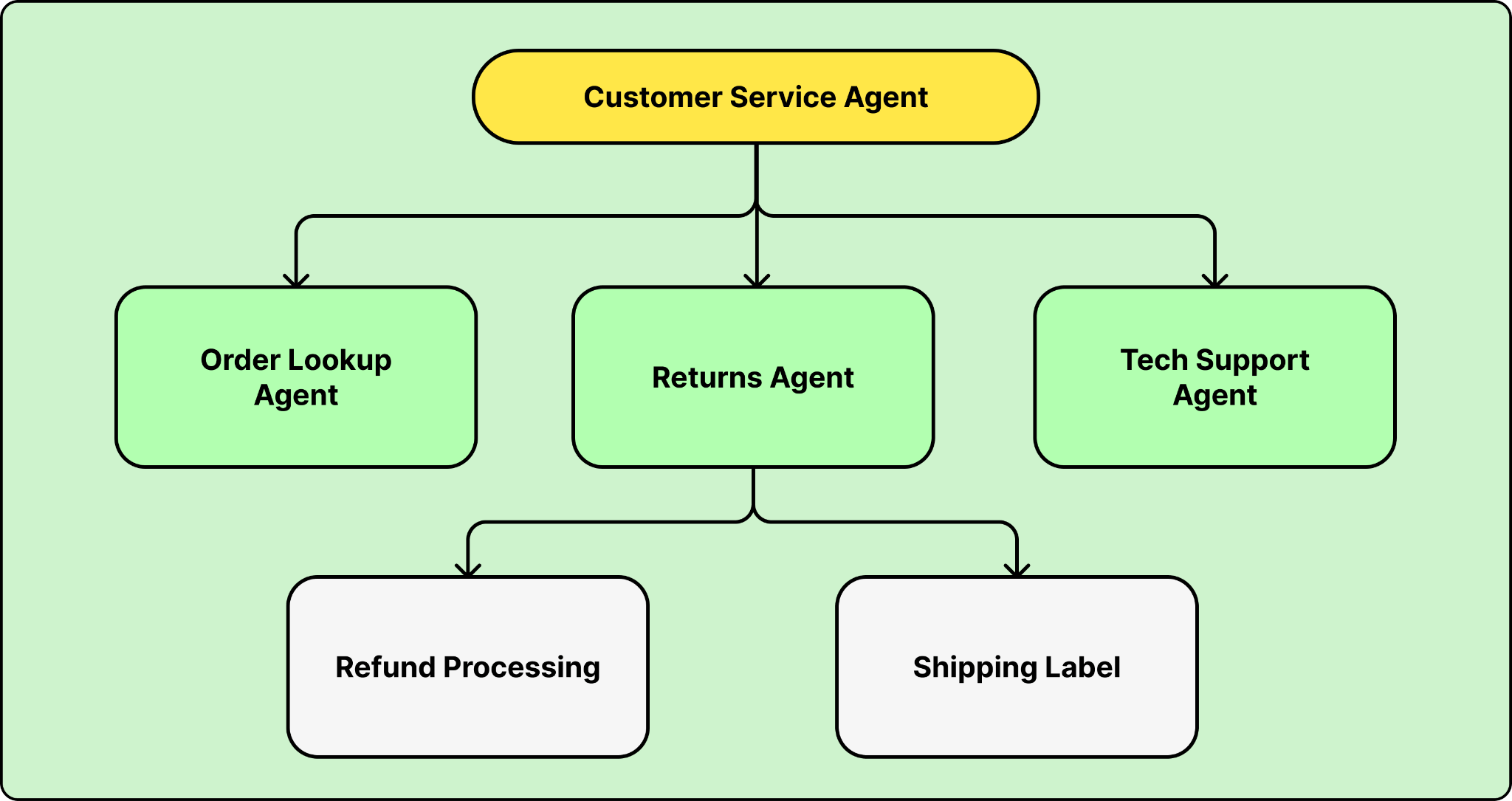
Salesforce is already building orchestration systems that go three levels deep: a parent agent with sub-agents, where each sub-agent can have its own sub-agents.
For developers, this changes how you architect agent systems. Instead of one large agent that handles everything, you decompose the problem into specialized agents that hand off to each other. Each agent has a narrower scope, which means simpler instructions, fewer tools, and a smaller context window.
Today, most agents live inside a chat widget. But the use cases emerging at enterprise scale go well beyond that. They include multi-session tasks that span days (like a tier-2 support case or a return authorization workflow), background agents that run with no user-facing interface at all, and agents that work across channels like phone, email, web, and Slack.
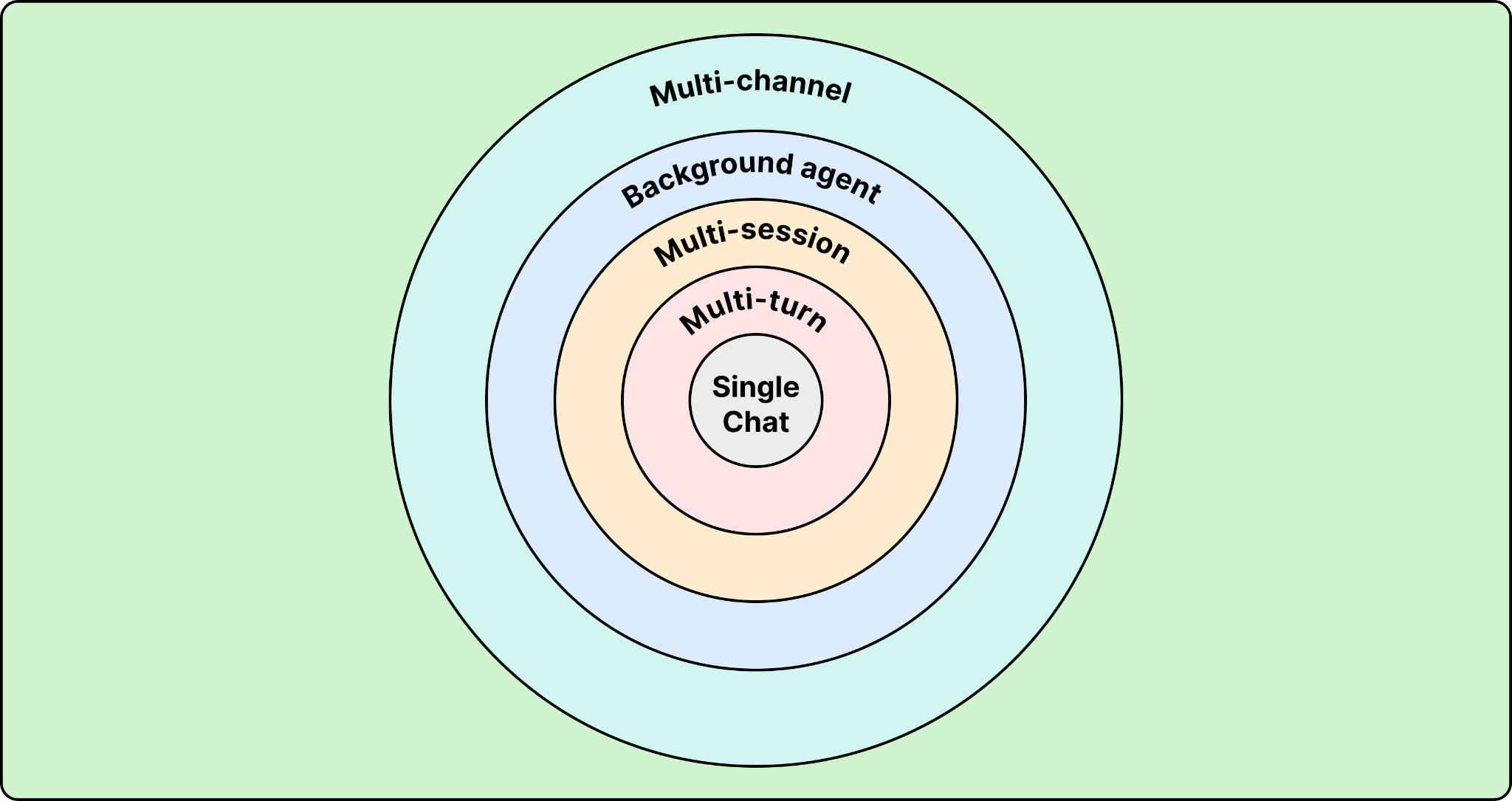
For developers, the takeaway is to avoid coupling your agent architecture too tightly to a chat interface. The agent’s logic, tools, and policies should be independent of the delivery channel. Teams building on Agentforce today are already running the same agent across web chat, phone (via Agentforce Voice), and background automation.
One thing that came up repeatedly in our conversation is how fast this space is moving. Coding agents, for example, went from basic assistants to highly capable tools in just a few months. The models are getting faster. The tooling is getting better. What’s considered best practice today may look different six months from now.
Building enterprise agents is still early. The models, tooling, and best practices are all moving fast. But the core engineering disciplines hold. Start small. Measure what matters. Build tight feedback loops. Encode policies in code, not prompts. Keep your context lean. These aren’t tricks tied to any specific model or framework. They’re how you build agents that work at scale.



