

[ad_1]
On June 10, GitLab Transcend streams live from London with an agenda built for practitioners like you. You can expect an agenda that’s full of keyboard moments with live demos of Duo Agent Platform, agentic AI use cases from your peers, and The Developer Show hosted live by Senior Developer Advocate, Colleen Lake. Register today.
GitLab Transcend streams live from London on June 10 (with regional replays for APAC and AMER on June 11). Register for free today.
In November 2023, Vercel quietly shipped an internal platform that cut its build provisioning time from 90 seconds to 5. That sounds like a story about making things faster. It is, but only on the surface. The real story is that Vercel got faster by accepting a harder constraint, building a more complicated foundation, and then layering three separate optimizations on top of it. The 18x improvement is the result.
Vercel is a deployment platform for web applications. When a developer pushes code to a connected repository, Vercel pulls that code, runs the build process (compiling, bundling assets, packaging the output) on its own servers, and then deploys the result to a global edge network of geographically distributed servers that deliver the site to end users. The build step happens on Vercel’s infrastructure, which means thousands of customers run their build scripts on machines that Vercel manages. Every push has to feel instant to the developer, has to run safely on shared hardware, and has to scale through traffic spikes without degrading.
The platform that handles all of this is internally codenamed Hive, and it has been powering Vercel’s builds since late 2023.
Hive is the reason behind the 90-to-5 transformation. In this article, we examine the constraints Vercel faced, the choices they made in response, and the optimizations that produced the speedup.
Disclaimer: This post is based on publicly shared details from the Vercel Engineering Team. Please comment if you notice any inaccuracies.
The architecture rests on a single foundational assumption. Hive operates as if every piece of code it executes might be malicious, running on machines shared by many tenants at once. That assumption influences everything that follows.
It matters because the trust calculation flips entirely between two situations. When a team runs its own code on its own server, the goal is performance and convenience. The code trusts the machine, and the machine trusts itself. When the code comes from someone else and runs on shared hardware, the calculation changes. The platform has to assume the code might try to break out of its sandbox, read another customer’s secrets, or interfere with builds running on the same machine. This is hostile multi-tenancy, and it is a different infrastructure problem from running cooperative workloads.
Vercel sits squarely in this harder category.
Every customer push is, from Vercel’s perspective, code written by someone the team has never met, running on a machine that is also running other customers’ code at the same time. The build script could be a normal Next.js compilation, or it could be a deliberately crafted exploit designed to escape the sandbox. Vercel has to handle both cases identically, since the platform cannot tell the difference in advance.
The obvious answer is to run each build inside a Docker container.
Containers are how modern infrastructure runs isolated workloads, and most engineers reach for them by reflex. The problem is that containers were designed primarily as a packaging tool, with isolation as a useful side effect. Multiple containers on the same machine all share the same Linux kernel, which is the part of the operating system with direct access to the hardware. Anything that breaks through the kernel can reach other parts of the machine.
For most workloads, this risk is acceptable, since most workloads are cooperative. A team’s own microservices have no incentive to attack each other. However, for running strangers’ build scripts at scale, the risk profile is different. A single kernel exploit in one customer’s build could reach every other customer’s build on the same machine, and the blast radius would be enormous.
This is why standard container orchestration was a poor fit.
Tools like Kubernetes assume cooperative tenants and provide good isolation by default, but not adversarial isolation. Adding hardening on top of Kubernetes was an option, but for a constraint as foundational as tenant isolation, building from primitives gave Vercel more leverage. Containers leave a gap that Vercel could not afford to leave open. The question was how to close that gap without giving up the speed that containers provide.
See the diagram below that offers some insight:
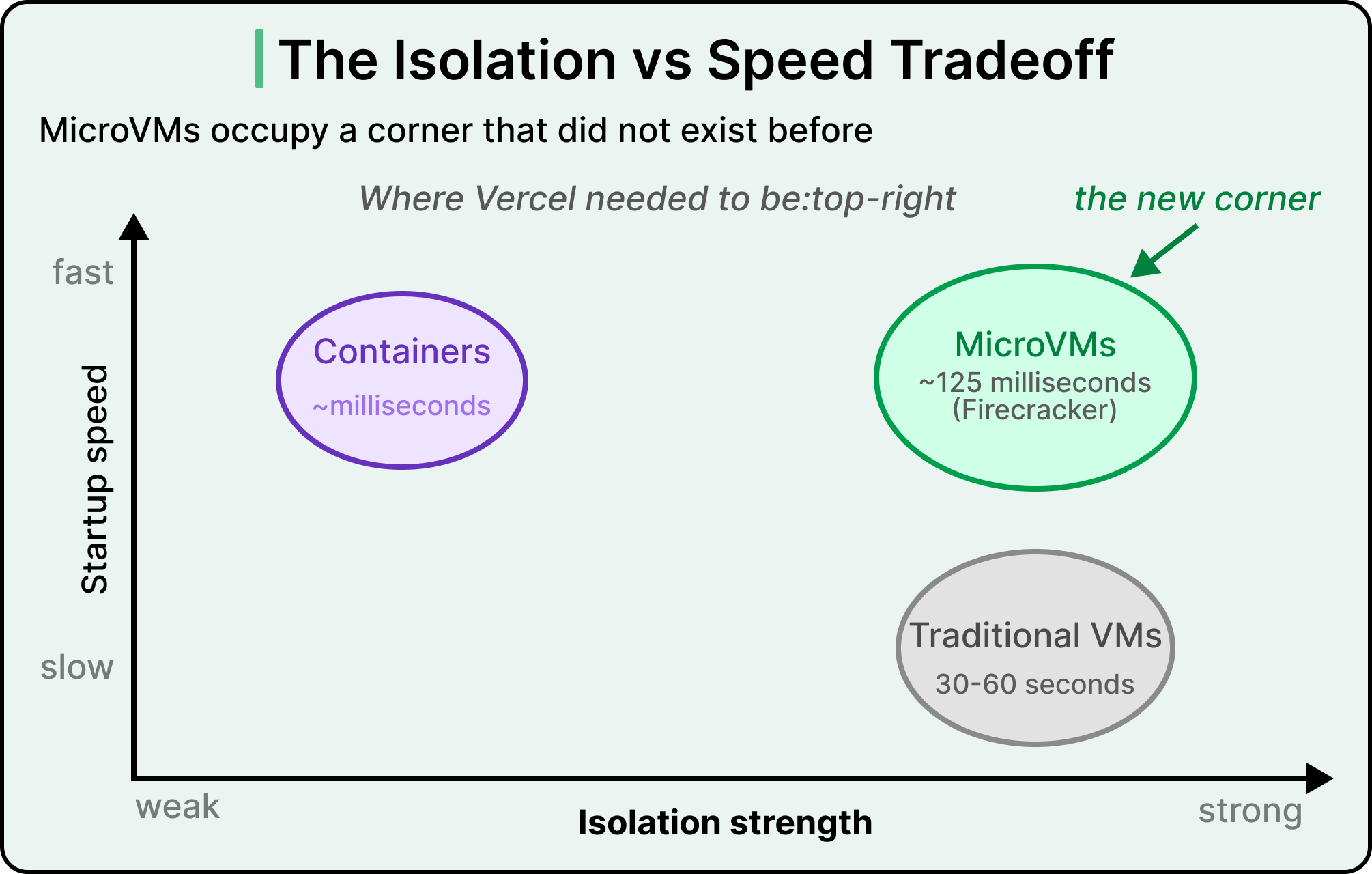
The traditional alternative to containers is the virtual machine.
A virtual machine runs a complete operating system on top of a virtualization layer, which means two VMs on the same physical machine each have their own kernel. A kernel exploit in one VM cannot reach the other, since the kernels are genuinely separate. The downside is weight. A traditional VM might take 30 to 60 seconds to boot and consume hundreds of megabytes of memory just to exist. For a workload like web hosting, where a single VM runs for months, that overhead is fine. For a workload like running a 2-minute build and then throwing the environment away, it becomes wasteful.
Around 2018, AWS released Firecracker, an open-source virtualization tool that strips a VM down to the minimum needed to run one short-lived workload.
Firecracker microVMs boot in around 125 milliseconds and use only a few megabytes of memory each. They provide VM-level isolation, with separate kernels and a hardware-enforced boundary that the CPU itself maintains, at something close to container-level speed. This is a new shape in the isolation tradeoff space, occupying a corner that did not exist before.
AWS originally built Firecracker to power Lambda, where it now runs at production scale across millions of concurrent functions. That track record gave Vercel a battle-tested foundation rather than an experimental one.
Vercel adopted Firecracker as the core of Hive. Each customer build runs in a microVM that Vercel calls a cell, and the relationship between cells and Firecracker processes is strictly one-to-one. Each Firecracker process manages exactly one cell, and each cell handles exactly one build. Inside the cell sits a container that runs the actual build script. The container handles packaging, since it carries all the build tools and dependencies the customer’s project needs. The microVM handles isolation, since it provides the kernel-level boundary that containers alone cannot. Each layer does what it is good at.
This setup is the architectural answer to the trust problem.
Vercel can now run a strange piece of code with confidence that, even if the code attempts something hostile, it cannot reach beyond the cell it is running in. The microVM is the wall, and the wall is enforced by the CPU’s virtualization features rather than by software alone. Firecracker provides the isolation primitive, while the rest of Hive is the machinery that turns one isolated cell into a system capable of running thousands of builds across the world.
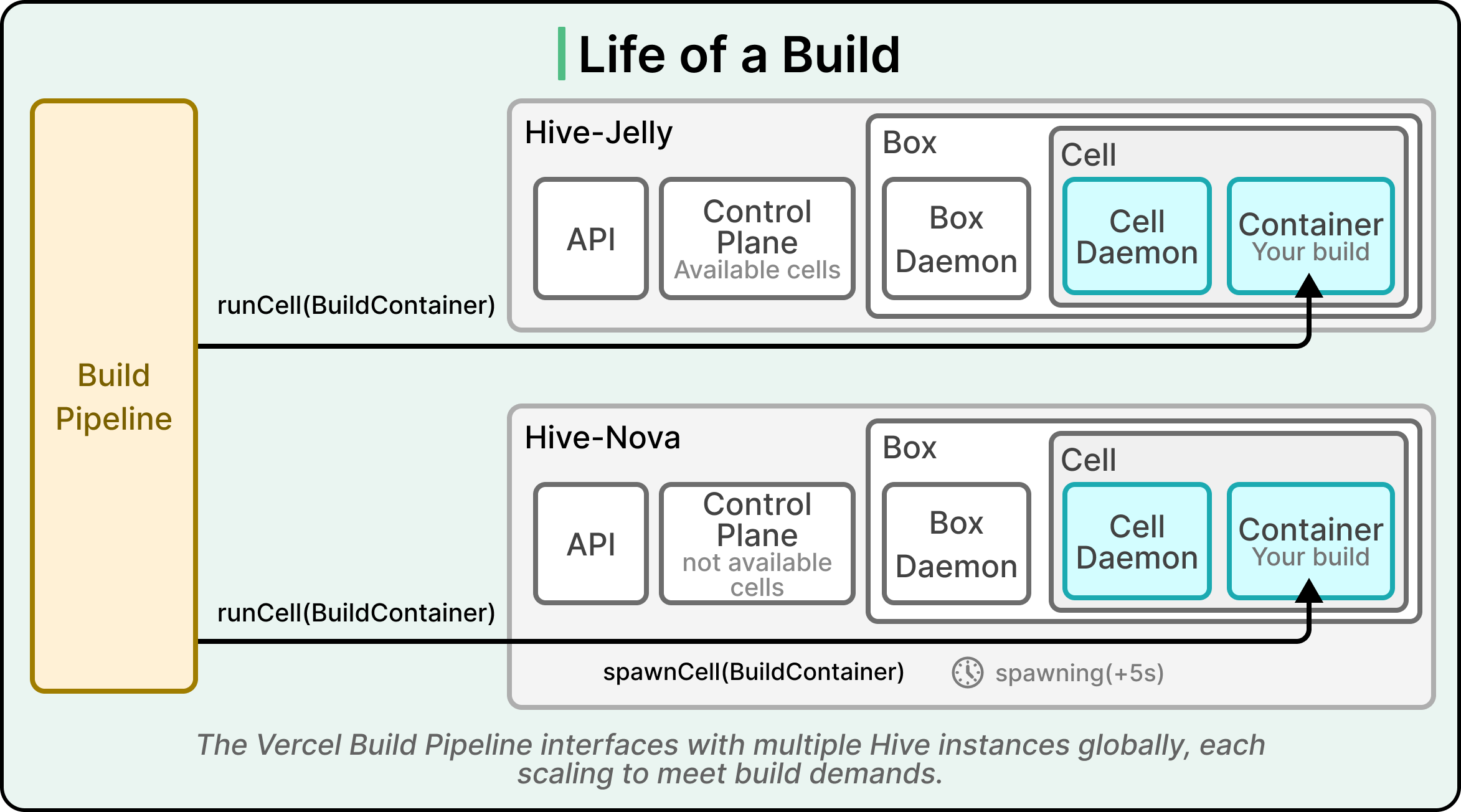
Hive has a small vocabulary, since the names map directly to physical and logical pieces of the system.
-
A Hive is a regional cluster, and multiple Hives can exist in a single region.
-
A Box is a physical machine inside a Hive.
-
A Cell is a microVM running on a Box.
-
The Control Plane is the brain of the cluster, and the API is the entry point that the rest of Vercel’s systems talk to.
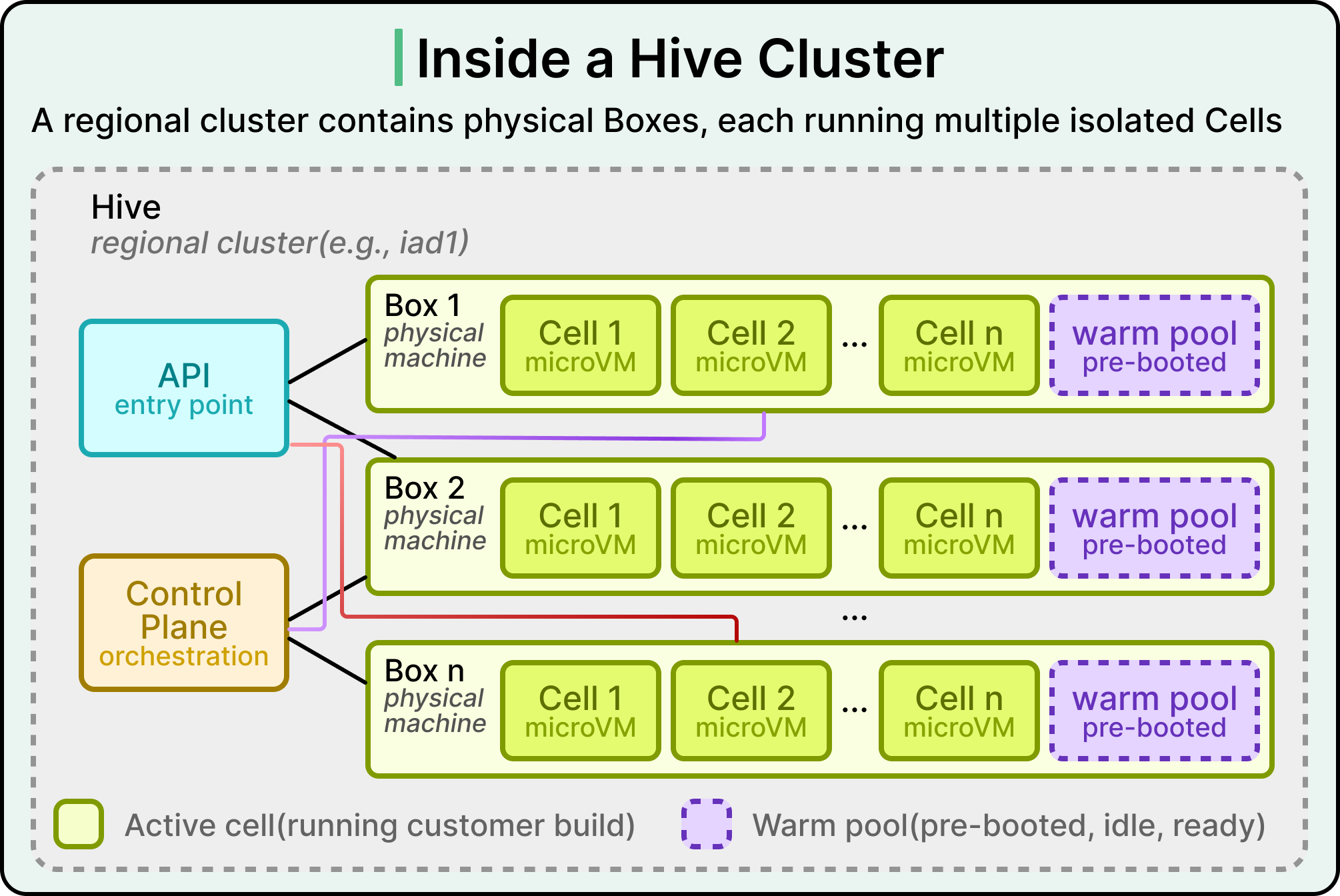
Here is a different view of the same diagram:
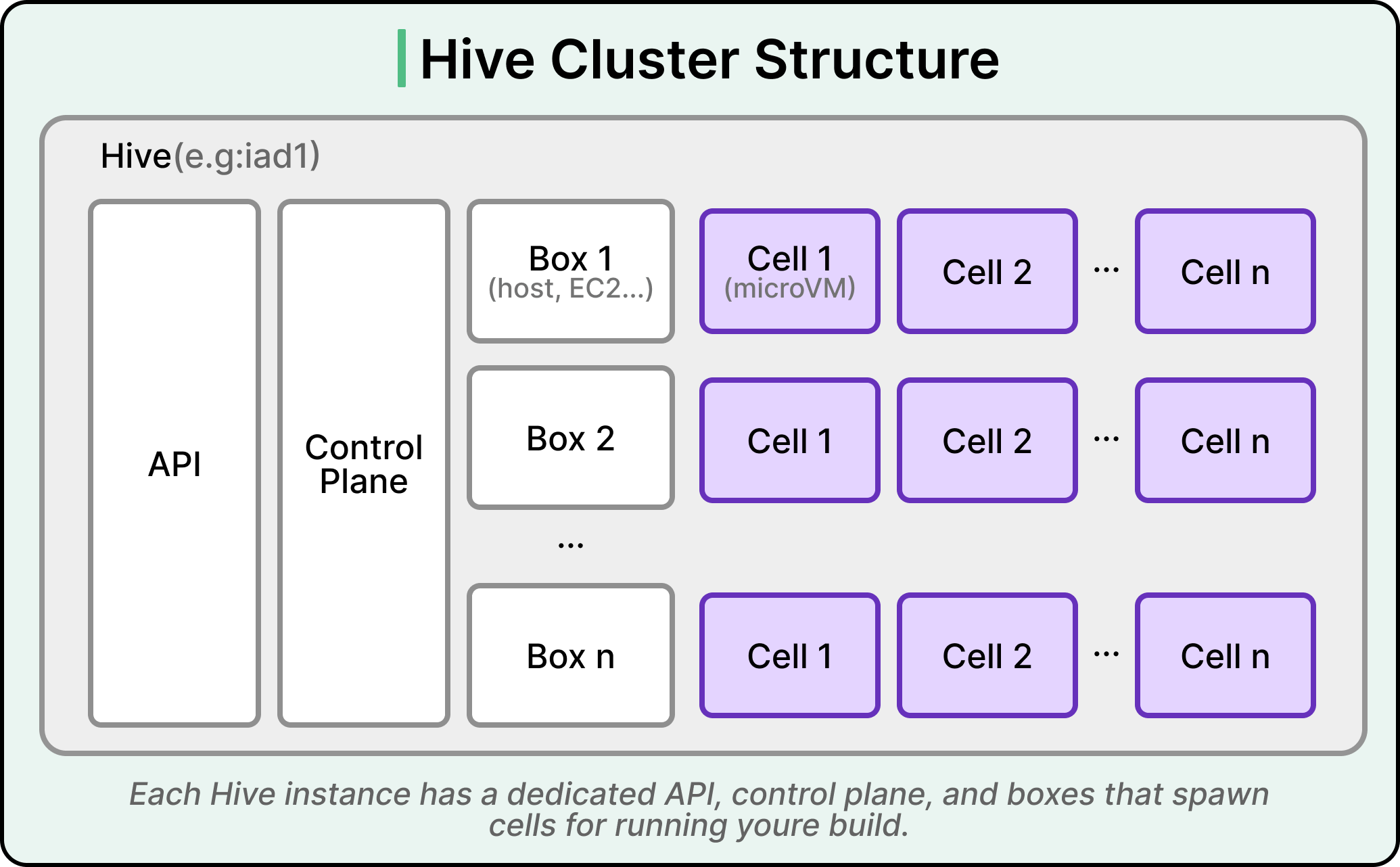
When a customer pushes code, Vercel’s build pipeline (which is a separate system from Hive) decides which Hive to use based on the customer and the build configuration, and then calls that Hive’s API to request a cell. The Control Plane finds an available cell on one of the Boxes, hands it to the build pipeline, and the build runs inside the cell’s container. Once the build finishes, the cell is destroyed, and the resources return to the pool.
Running multiple Hives per region is a deliberate failure isolation choice. If one Hive has a bad day, the others in the same region keep running. This is finer-grained reliability than running in multiple cloud regions alone, and it means a single bad deploy or infrastructure incident will not take out an entire customer base.
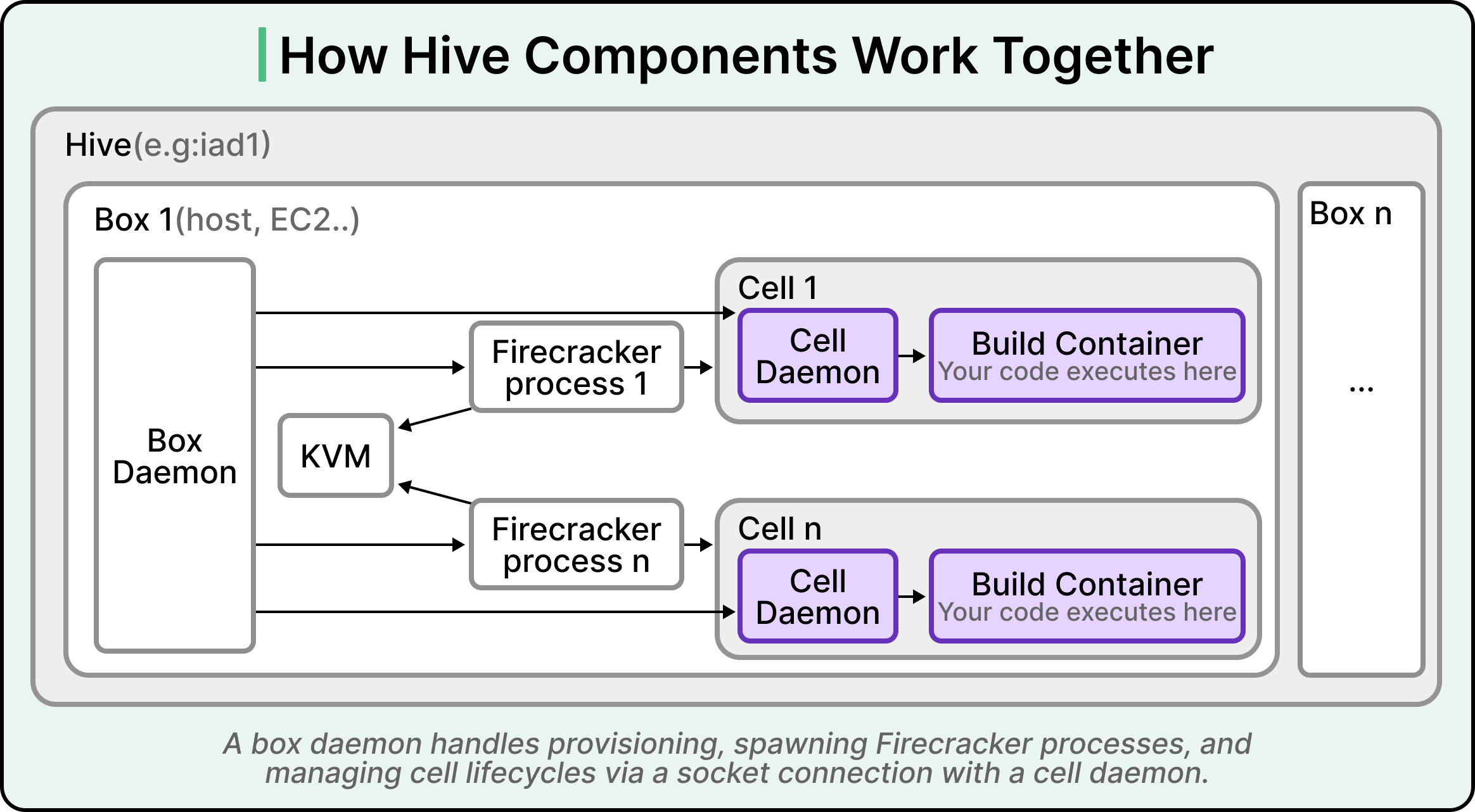
Two background programs handle the orchestration inside each Box.
-
A box daemon runs on the physical machine and handles provisioning, spawning new Firecracker processes, and managing the lifecycle of cells.
-
A cell daemon runs inside each microVM and manages the build container that does the actual work.
The two daemons communicate over a socket connection, which is how the orchestration layer scales without becoming a bottleneck. The pattern matters more than the implementation. Responsibility is split between the host machine and the virtual machine, and each side has a clear job.
See the diagram below:
Each cell receives dedicated CPU and memory, which means those resources are partitioned cleanly between cells on the same Box. Disk and network throughput, however, are rate-limited based on the Box’s overall capacity rather than dedicated.
This reflects where multi-tenant isolation hits its practical limits. Some resources are easy to slice up, while others must be shared with quotas because slicing them cleanly would waste too much capacity.
The other architectural choice is that these cells are ephemeral. Once a build completes, the cell is destroyed rather than reused, even though reusing it would be faster. This is a security choice rather than a performance one. A reused cell would create a path for one customer’s leftover state, whether that means files on disk, processes still running, or memory contents, to leak into another customer’s environment. Destroying the cell after every build closes that path entirely.
All of this architecture would still be slow if every build had to spin up a fresh cell from scratch. Even with Firecracker, the cold path takes about 5 seconds per cell, since the system has to boot the microVM, mount the disk, load the build container image, and start the container.
The 18x improvement comes from three places.
The first layer is faster boots. Inside each Box, Vercel optimized the cell startup path itself. The build container image is large, so pulling it fresh on every cold start used to add significant time. Vercel now caches the build container image so it loads from a local copy rather than from a remote registry, and that change alone shaved around 45 seconds off VM startup times compared to their previous solution. They also use block device snapshotting, where the disk image of a freshly prepared cell is saved at a known-good moment, and new cells start from that saved copy instead of building up from scratch. These optimizations make the cold path itself dramatically faster.
The second layer is the warm pool, and this is where most of the speedup happens. Vercel keeps a pool of cells already booted, with the build container image loaded, sitting idle and waiting. When a build comes in, it uses a warm cell and starts running immediately. The 5-second provisioning time only applies when the warm pool is empty, which happens during traffic spikes or for specialized builds like Secure Compute (an enterprise feature with stricter isolation requirements). For the common case, the wait is essentially zero. The warm pool means that most builds skip cold-start provisioning entirely.
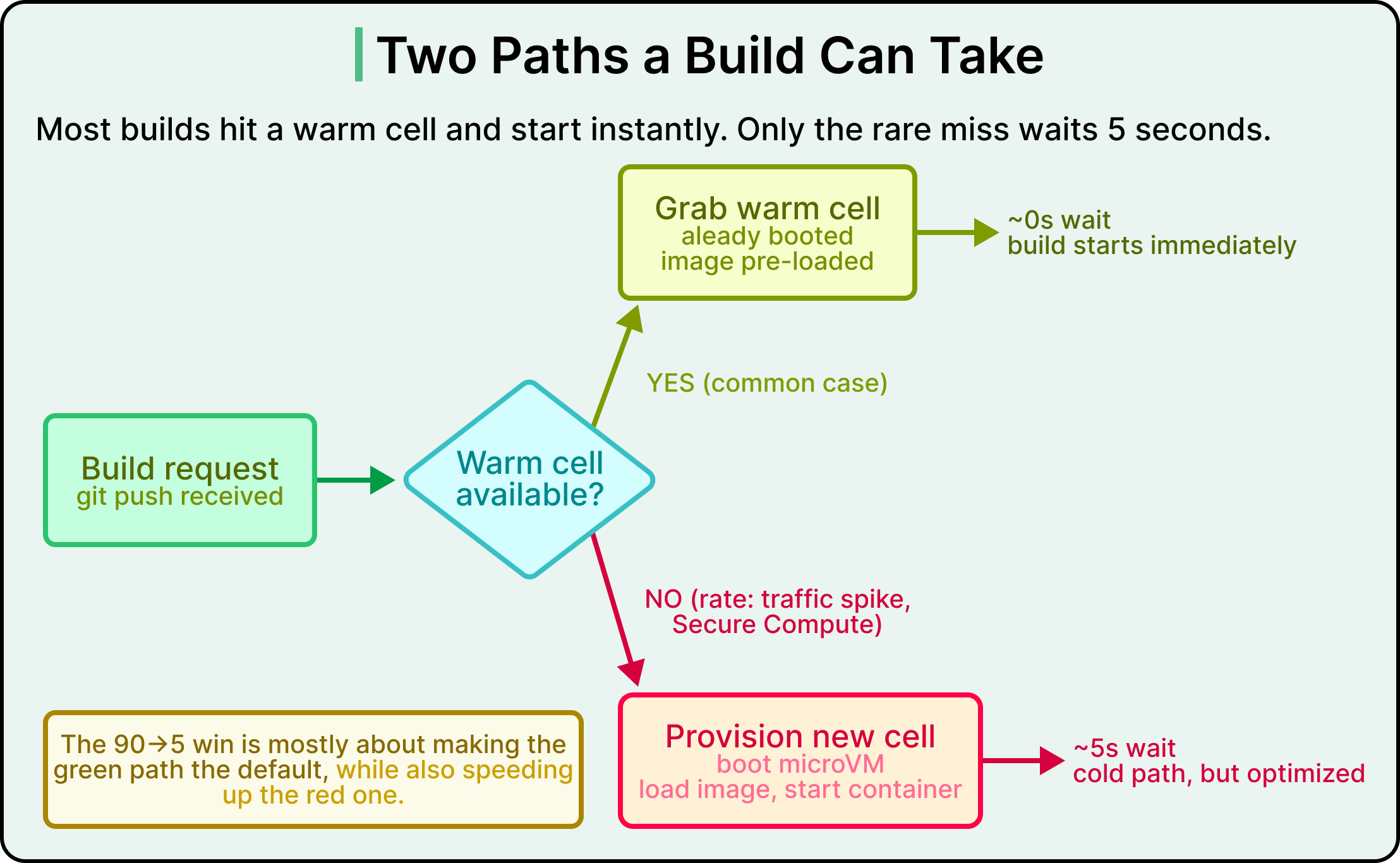
The third layer is Firecracker’s baseline speed. None of the other features would matter if the underlying virtualization were heavy. Traditional VMs take tens of seconds to boot, which makes warm pools impractical at scale, since the pool would have to be enormous to keep up with demand. Firecracker boots in milliseconds, which is what makes warm pools and snapshotting work in the first place. The whole speed story rests on the foundation Vercel chose at the very beginning.
Across all builds, Vercel saw a 30% improvement in build performance after switching to Hive. Builds that hit the cold path, where a fresh cell has to be spawned, saw build times drop by about 40%. The provisioning portion of those cold-path builds dropped from 90 seconds to 5. None of these numbers came from a single breakthrough. They came from compounding wins on a foundation that allowed them.
Warm pools come with a real trade-off in terms of cost.
Keeping cells pre-warmed means Vercel pays for compute that does no useful work most of the time. The amount is substantial, since the right pool size is a constant balance between waste, where too many idle cells burn money, and tail latency, where too few warm cells leave customers waiting during traffic spikes. For a service with bursty traffic, this is an active operations problem rather than a one-time tuning.
Building Hive at all was the higher cost. Vercel could have used Kubernetes or ECS and added isolation on top, and they would have shipped something serviceable in a fraction of the time. Building from primitives required enormous engineering investment and an ongoing maintenance burden that off-the-shelf tools would have absorbed for them. The reason it was worth doing is that owning the substrate gave Vercel leverage that an opinionated platform would have caused difficulty. The team can make decisions like destroying every cell after every build, or tuning the warm pool based on customer build patterns, without working around someone else’s design.
The payoff for that leverage is visible in product features. The same architecture that drove the 90-to-5 number also enabled Vercel to ship enhanced build machines for customers who need extra memory or disk, and to support Secure Compute for enterprise customers with stricter isolation requirements. These features would have been much harder to build on top of a third-party platform, since they would have required either accepting the platform’s constraints or fighting them at every step. Building the foundation paid off in product capabilities, not just performance numbers.
This architecture makes sense for Vercel because they have hostile multi-tenancy at scale, and because builds are core to their business rather than incidental to it. For a team running its own builds for its own code on its own machines, microVMs would be wildly over-engineered, and containers are perfectly appropriate. The lesson is the connection between threat model and architecture, rather than a generic recommendation to always use microVMs.
Vercel’s story illustrates a pattern that repeats across the industry. Threat model drives architecture. Cooperative tenants can run on containers and standard orchestration. Adversarial tenants require microVMs, isolated runtimes, or sandboxed execution environments. The shape follows from the assumption.
The broader takeaway from Hive is that Vercel got faster by accepting a harder problem rather than working around it.
Containers were inadequate for the trust model, microVMs were the right shape, and the speed came from stacking three separate optimizations on top of a deliberately harder foundation. Starting with the constraint and then optimizing for the speed proved to be a stronger bet than starting with the simple thing and trying to make it run quicker.
References:
[ad_2]
Source link
 and take advantage of Amazon's killer new Razr FIFA World Cup 26 deal!")

