

[ad_1]
AI workloads are exposing the limits of what most databases were designed to handle. Databases will need to process petabytes of data, millions of writes per second, and data types like vectors – all while delivering consistent sub-millisecond P99 latency.
Join ScyllaDB co-founders Dor Laor (CEO) and Avi Kivity (CTO) to explore what real-time AI workloads actually require, and what it takes to stay ahead.
You will learn:
-
How AI workloads are shifting in real-world applications
-
The specific pressures these new patterns place on databases
-
What architectural features help teams meet AI’s demands
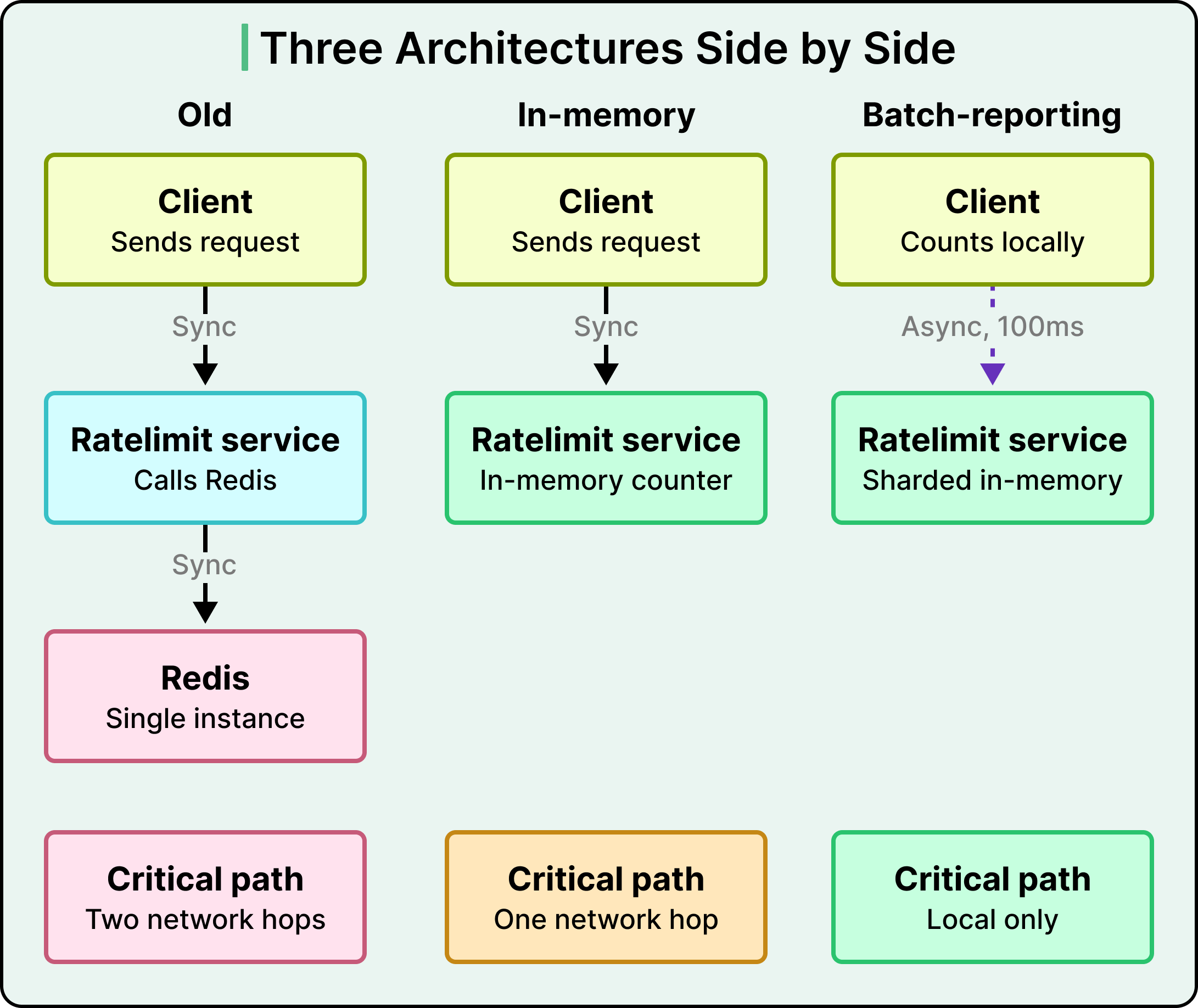
In early 2023, the Databricks rate limiter ran on a simple architecture. An Envoy ingress gateway made calls to a Ratelimit Service, which in turn queried a single Redis instance. The setup handled the traffic it was designed for, and the per-second nature of rate limiting meant the counts could stay transient without any durability guarantee.
Then, the real-time model serving was launched. A single customer could now generate orders of magnitude more traffic than the service was built for, and three specific cracks appeared.
-
Tail latency climbed sharply under load, worsened by two network hops and a P99 of 10 to 20 milliseconds between services in one cloud provider.
-
Adding machines and bolting on caches stopped helping past a certain point.
-
The single Redis instance also represented a single point of failure that the team could no longer tolerate.
The team redesigned the service, and the rebuild merits attention because the most interesting part is what they chose to give up.
Strict accuracy is expensive at scale, and Databricks traded it for a faster critical path, a horizontally scalable counter, and a rate limiter that answers as if the decision has already been made by the time the client checks.
In this article, we look at how Databricks implemented rate limiting at scale, how they shrank the critical path, and the accuracy tradeoff that shrinking usually requires.
Disclaimer: This post is based on publicly shared details from the Databricks Engineering Team. Please comment if you notice any inaccuracies.
Strip away the framing, and rate limiting reduces to a counting problem. Each request arrives, the system locates the right counter, compares it against a threshold, and either allows or rejects the request. The design question is where that counter is stored and how quickly it works.
In the old Databricks architecture, the counter was stored in Redis. See the diagram below:
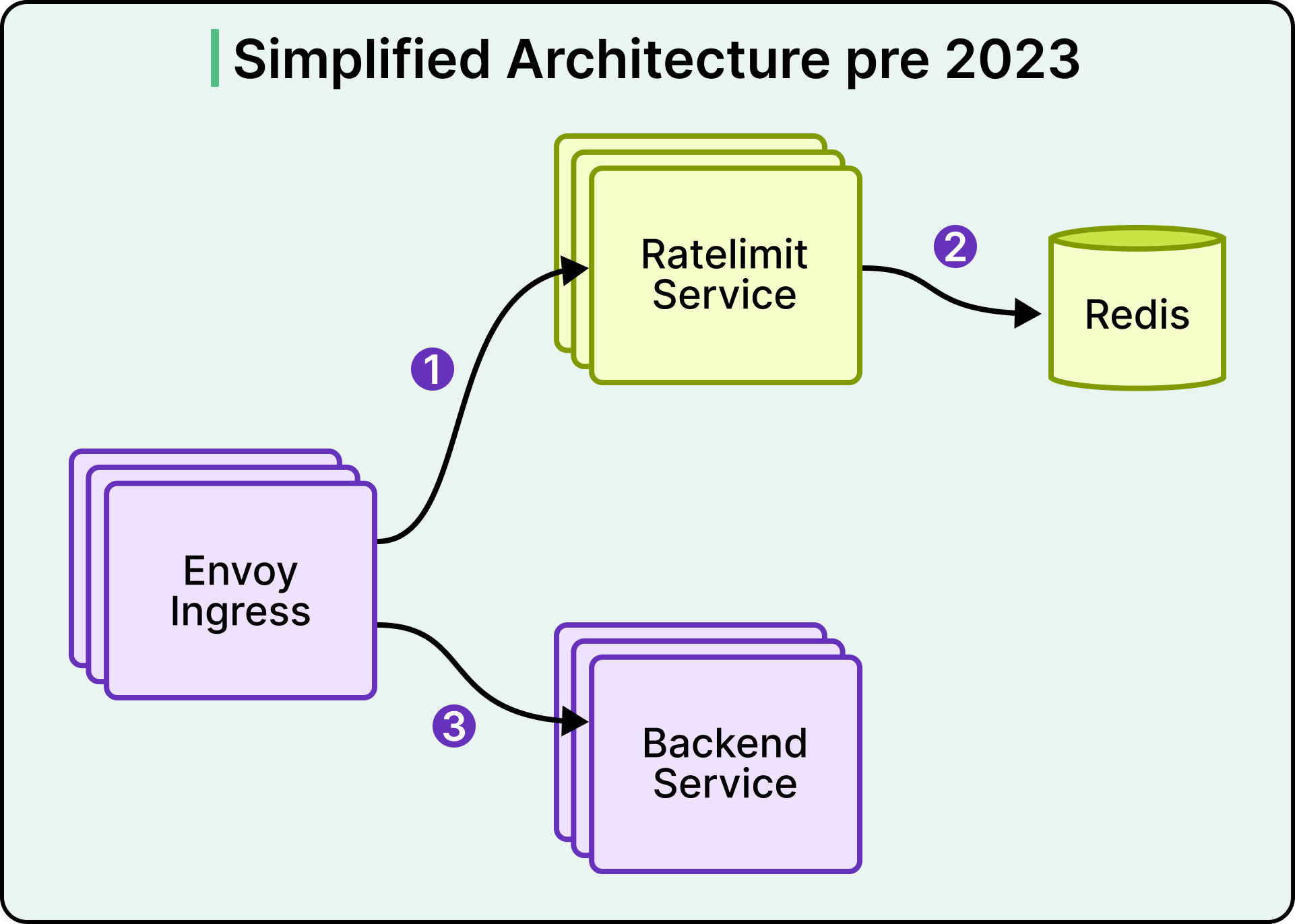
A request flowed through Envoy, hit the Ratelimit Service, and triggered a call to Redis. That meant two network hops on the critical path of every request. In a cloud provider where P99 network latency sat between 10 and 20 milliseconds, those hops dominated the rate limit decision time. A check that should have cost microseconds was costing tens of milliseconds.
See the diagram below:
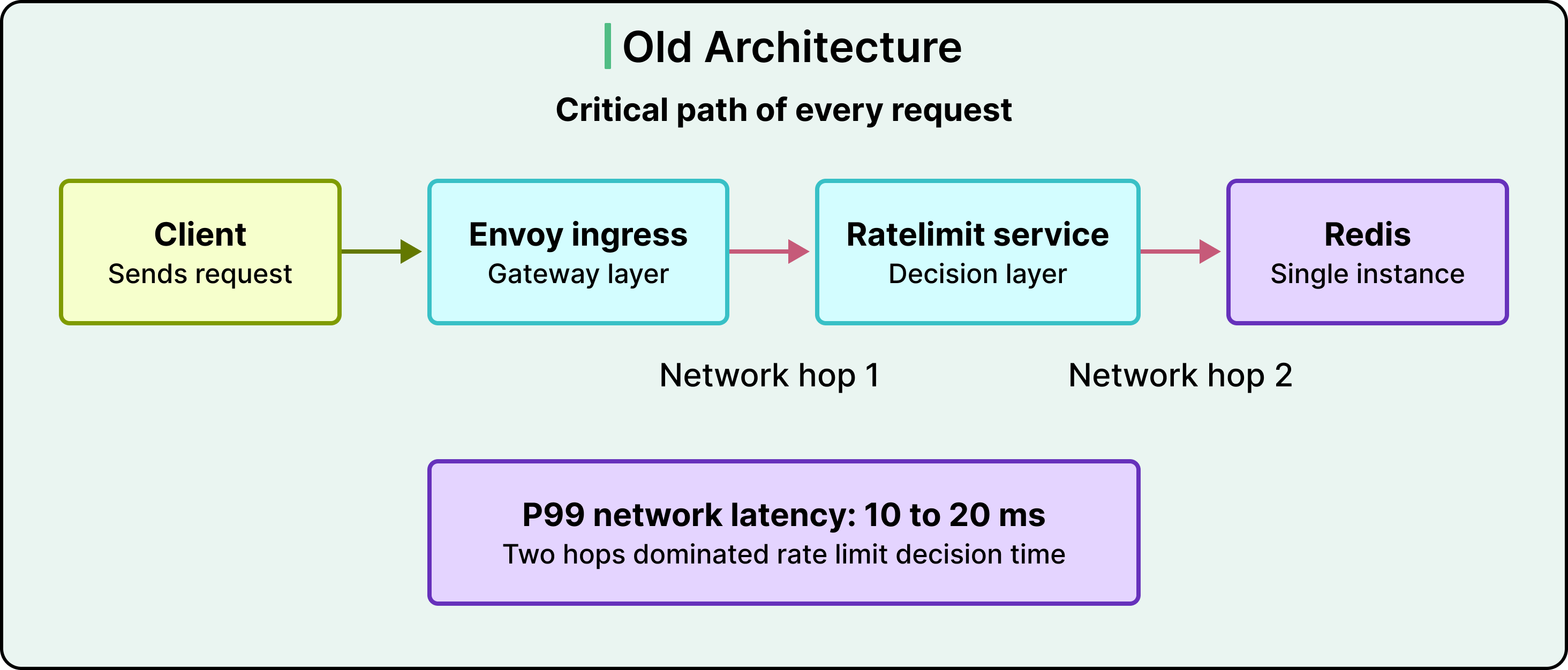
The team had already tried to work around this. Envoy can be configured with consistent hashing so that requests with the same key land on the same Ratelimit Service instance, which lets that instance keep a local count. The approach helped, but it hit three walls.
-
Non-Envoy services could not participate in the scheme, which fragmented the rate limit view.
-
When the service cluster scaled up or restarted, the hash assignments churned, which forced regular syncs back to Redis.
-
Lastly, consistent hashing can be prone to hotspotting, where one very popular key saturates a single machine while its neighbours sit idle. The only way to push through those hotspots was to over-provision the entire cluster.
This is where scaling stops being additive. Adding machines stopped moving the latency numbers, and adding more caching introduced more inconsistency. The architecture itself was the ceiling, and the team had to change it.
Rate limiting is transient. A per-second count exists only as long as that second is current, and the moment it rolls over, the old value becomes irrelevant.
That property opens a door. If a count only needs to live for a second, durable storage is more than the problem requires. The count can live in memory on the server that owns it, and losing that server during a restart costs almost nothing.
The challenge is that a single server cannot hold counts for every rate limit key across the fleet. The service needs a way to partition keys across servers, and a way for any client to quickly find the server that owns a given key.
That is the problem Dicer solves at Databricks. For the purposes of this discussion, Dicer can be treated as a black box. Dicer is a routing layer that lets a service keep state in memory while remaining horizontally scalable and fault-tolerant. Clients ask Dicer which server owns a given key, and that server confirms it is the authoritative owner before handling the request.
See the diagram below:
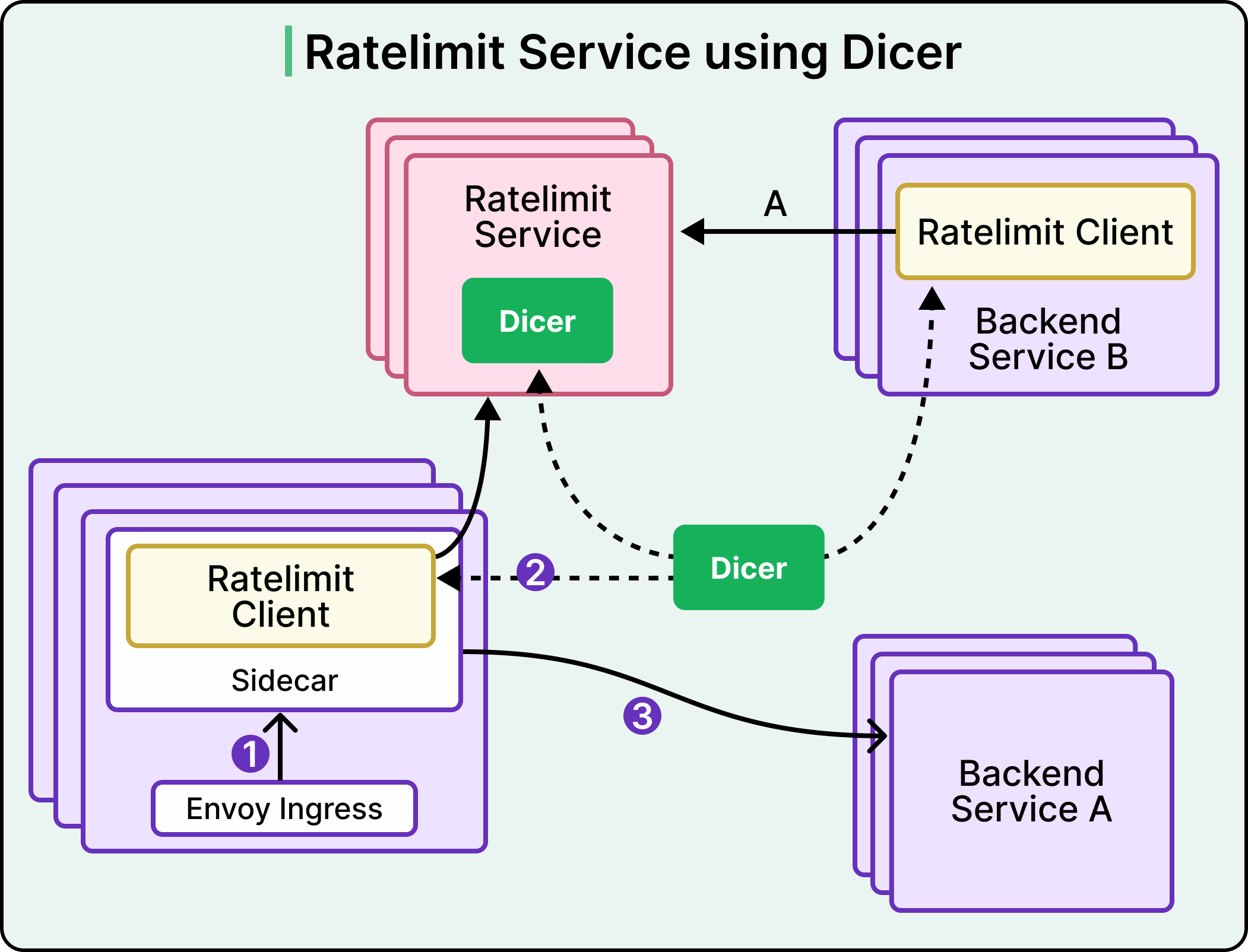
With Dicer in place, the Ratelimit Service could move every counter in-memory. The network hop to Redis disappeared. Server-side tail latency came down sharply, and the team could scale horizontally by adding replicas to Dicer’s assignment pool. The single point of failure went away as well, because each replica became the authoritative store for its own slice of keys. Restarts and scale events redistributed ownership without any external coordination, and the churn that had forced Redis syncs in the old consistent hashing setup stopped having an impact.
This solved one problem and exposed another.
The server side was now fast, but the client side still made a synchronous call across the network for every single request. A rate limit check that had been waiting on Redis was now waiting on the Rate Limit Service. The P99 came down, but the shape of the problem remained. The critical path still had a round trip on it.
This is where the team made its most consequential move.
Millions of client requests per second were still translating into millions of synchronous calls to the Ratelimit Service. Even with the server answering in memory, that represented significant network traffic, significant server capacity, and significant client-side waiting. The team asked a harder question.
Does every request truly need to wait for a rate limit decision before proceeding?
They considered three alternatives:
-
The first was prefetching tokens on the client, where the client pulls a block of capacity and answers rate limit checks locally.
-
The second was batching requests on the client and waiting for a response before releasing them.
-
The third was sampling, where only a fraction of requests get checked.
Each had problems. Prefetching carries messy edge cases during startup, expiry, and token exhaustion. Batching adds delay and memory pressure. Sampling works for high-QPS limits but falls apart when the limit itself is small.
What the team built is called batch-reporting, and it rests on two ideas:
-
The first is that clients make no remote calls on the rate limit path.
-
The second is optimistic rate limiting, where the default is to allow the request and reject only when the client already has a reason to reject from an earlier report.
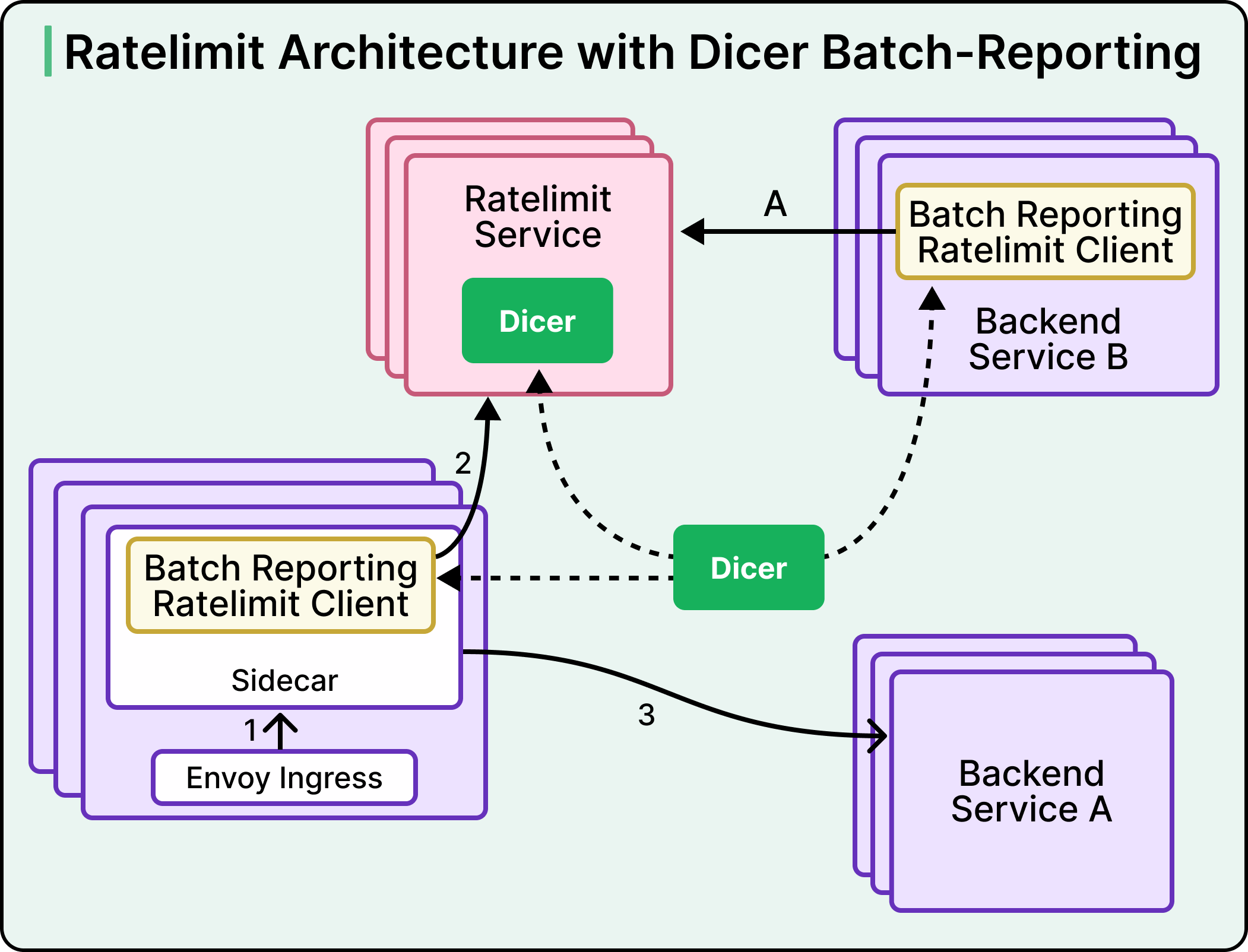
The client counts how many requests it let through and how many it rejected, grouped by rate limit key. Every 100 milliseconds or so, a background thread packages those counts and reports them to the Ratelimit Service. The server responds with instructions telling the client which keys should be rejected, until which timestamp, and at what rejection rate.
The diagram below shows the three architectures side by side:
The impact was substantial:
-
Tail latency on rate limit calls fell by roughly a factor of ten, because the calls were effectively free for the client.
-
Spiky inbound traffic turned into constant outbound reports because the reporting cadence is fixed regardless of how bursty the underlying traffic becomes.
-
Server-side load became predictable for the first time.
The inversion merits emphasis. The rate limiter used to be asked before each decision. Now it is told after. That inversion sits at the core of the redesign, and the tradeoff is explicit. Databricks accepts that some requests over the limit will slip through between reports, and their backends are built to tolerate that overshoot.
Batch-reporting introduced a problem of its own.
Between the moment a client starts exceeding a limit and the moment the server tells it to reject, traffic can leak through. A hundred milliseconds of overshoot at high QPS amounts to a lot of requests. The team wanted guarantees that kept overshoot within roughly 5 percent of the policy, and reaching that target required three-layered fixes.
The first was a rejection rate returned by the server. The idea is to use the past to predict the near future. If the last second’s traffic exceeded the policy by some amount, the formula rejectionRate equals (estimatedQps minus rateLimitPolicy) divided by estimatedQps tells the client what fraction of upcoming requests to drop. This assumes that the next second’s traffic resembles the last second’s, which often holds true to help.
The second was a client-side local rate limiter as a defense in depth. When traffic spikes so obviously that the batch cycle has no chance of catching up, the client starts rejecting locally based on its own counts. This catches the extreme cases immediately rather than waiting for a round trip.
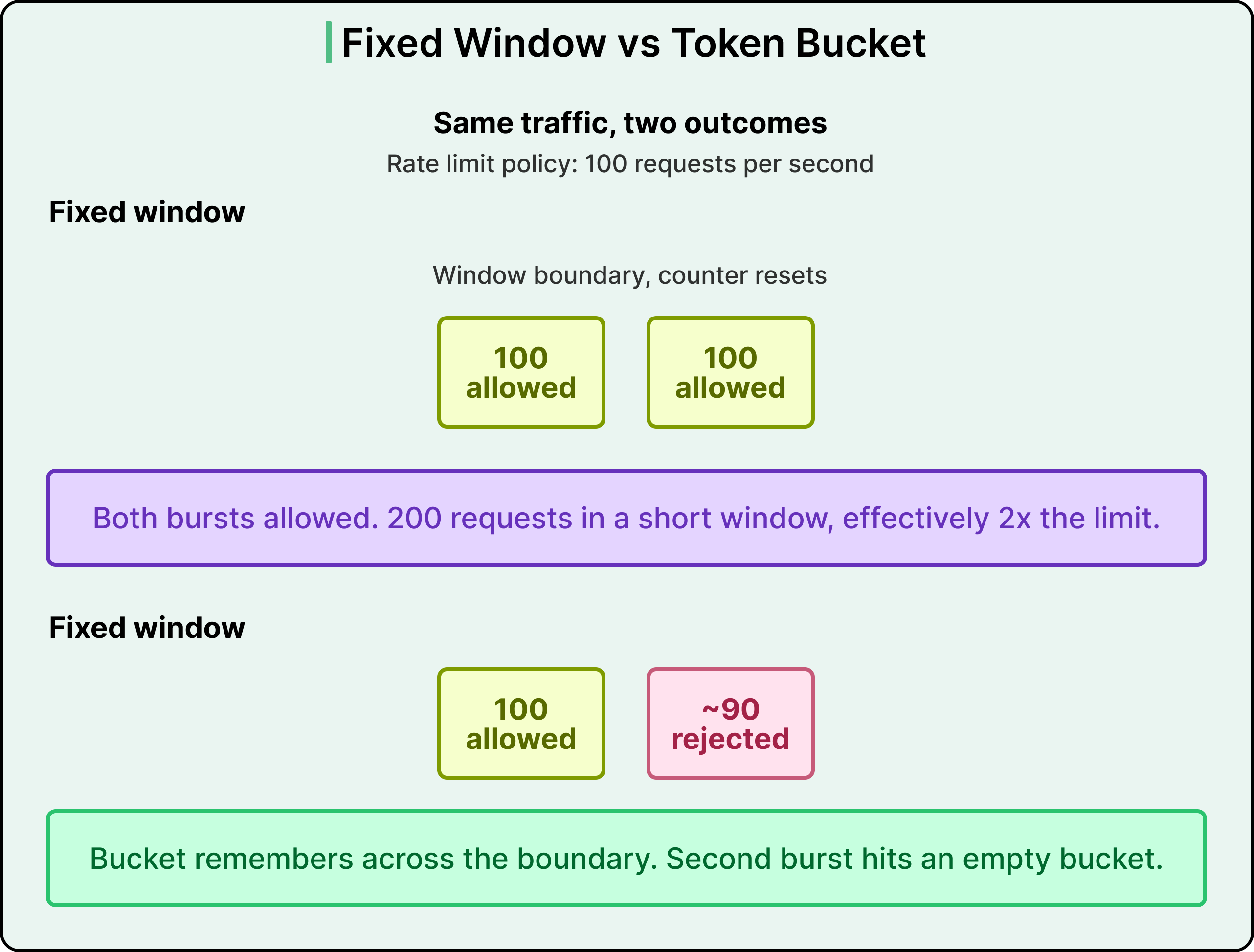
The third was the algorithm itself. Once autosharding lets the service hold counts in memory, the token bucket becomes feasible. The token bucket has a useful property that a fixed window lacks. Fixed window resets to zero at the end of every interval, so a customer can blast traffic right at a window boundary and technically stay within the policy while sending double the intended rate during the crossover. The token bucket continuously fills and drains, and it can go negative. When a customer sends too many requests, the bucket remembers and stays empty until the refill catches up. The reset problem disappears. Token bucket also approximates a sliding window when configured without extra burst capacity, which produces a stricter shape than a fixed window for most limits.
This is where the algorithm choice was gated by the storage choice. Token bucket needs compare-and-set style logic on every increment, which was slow in Redis. In-memory, the same operation is close to free. Once the token bucket was viable, the earlier rejection rate mechanism became unnecessary, and the team eventually converted every rate limit in the system to a token bucket.
The Databricks story resolves into three decisions that depend on each other:
-
The first is the algorithm, which determines how the counter behaves at the boundaries of time intervals. Fixed window, sliding window, and token bucket each produce different behaviour in that regard.
-
The second is where the state lives, whether in a shared external store like Redis, in an in-memory counter on a single server, or in an in-memory counter sharded across a cluster of servers through some routing layer.
-
The third is the sync model, which can either require every request to wait for a synchronous decision or allow clients to make local decisions and reconcile through asynchronous reports.
The old Databricks architecture sat at one corner of that space, combining a fixed window, shared Redis, and synchronous per-request checks. The new architecture sits at a different corner, combining token bucket, sharded in-memory storage, and asynchronous batch reports.
The dependency chain is worth understanding. Token bucket needs cheap compare-and-set semantics, which rules out Redis at the QPS Databricks sees, which forces in-memory state. In-memory state across many counters forces sharding, because one server cannot hold everything. Sharding with authoritative per-key ownership is what enables batch-reporting, because each shard can act as the source of truth for its keys without coordinating with peers.
These constraints explain the order of the rollout. Sharded in-memory came first, batch-reporting followed on top of it, and token bucket replaced the algorithm once the state architecture could support it.
The end result is a rate limiter that is faster, more resilient, and more scalable than what came before, at the cost of strict accuracy. That tradeoff is the foundation of the design.
A system that has to enforce limits exactly, because each request over the limit costs real money or violates a contract, would have to pick a different architecture. Databricks could afford this one because their backends tolerate roughly 5 percent overshoot.
A few smaller details from the rollout are worth noting. The team built a localhost sidecar next to the Envoy ingress to host the batch-reporting logic, because Envoy is third-party code they could not change directly. Before in-memory counting was ready, a Lua script on Redis batched writes together to keep batch-reporting latency manageable during the migration.
The rebuild reframes what rate limiting is as a system problem.
The algorithm tends to get the attention, but the storage and sync model determine whether the algorithm can run at scale. Distributed counting is a single design problem with three coupled aspects rather than three independent ones.
References:
[ad_2]
Source link



