
AI shows up in 60% of engineering work. But only about a fifth of it can be handed off without someone babysitting the output. That’s because agents are missing context.
This 8-stage context maturity model gives a real answer on why you still get inconsistent output for all the tokens burned.
Join Unblocked live on June 24 (FREE) to learn:
-
Why more MCPs provides agents access but not understanding
-
What it takes to deploy agents you can trust without supervision
-
How a context layer solves for quality, efficiency and cost
This week’s system design refresher:
-
Claude Fable 5: Everything You Need to Know! (Youtube video)
-
12 Open-source LLMs
-
SLMs vs. LLMs, Clearly Explained
-
Single Agent vs. Multi-Agent Architecture
-
7 Permission Modes Every Claude Code User Should Know

Twelve models worth knowing in 2026, each with one standout strength.
-
Llama 4 Scout: Meta’s first natively multimodal open-weight model.
-
DeepSeek V4: A Mixture-of-Experts model under MIT license with a native million-token context window. Near-frontier performance at a fraction of the cost per token.
-
Qwen3: Alibaba’s flagship open-weight model with switchable thinking and non-thinking modes, all under Apache 2.0.
-
Gemma 4: Google’s open-weight family released under Apache 2.0, with the widest language coverage of any model on this list.
-
Phi 4: Microsoft’s compact model trained almost entirely on synthetic, curated data. A practical choice for edge and on-device deployment.
-
Mistral Small 3.1: A VLM with a long context window that fits on a consumer laptop.
-
Nemotron 3 Super: NVIDIA’s hybrid MoE with a million-token context window. Fully open weights, datasets, and recipes, with strong results on agentic coding benchmarks.
-
GLM 5.1: The first open-weight model to top SWE-Bench Pro. Released under MIT with no commercial restrictions.
-
Kimi K2.6: Competitive with leading closed models on coding while costing far less per million tokens. Available on Hugging Face under a Modified MIT license.
-
StarCoder2: One of the most transparent code models available.
-
OLMo 2 (AI2): The most complete example of open-source reproducibility on this list. Weights, training data, code, and full recipes all released under Apache 2.0.
-
Falcon 3: A family of lightweight open-weight models built to run on a single GPU.
Over to you: which open-source model would you add to this list?

Speed without control is a false economy. As AI code-generation accelerates software delivery, the FeatureOps Summit 2026 is here to ensure that when we ship more, we break less.This premier virtual event brings together engineers, architects, and product leaders from companies like Samsung, Lloyds Banking Group, Wayfair, Visa, AWS, Allianz and many others, to explore the infrastructure of fearless delivery.
Key Themes:
-
AI Safety Nets: Guardrails for the flood of automated code.
-
Edge Resilience: Sub-millisecond evaluation at scale.
-
Continuous Flow: Moving past the “fixed-release” mindset. Register today to master the tools and patterns required for a fail-safe release environment.
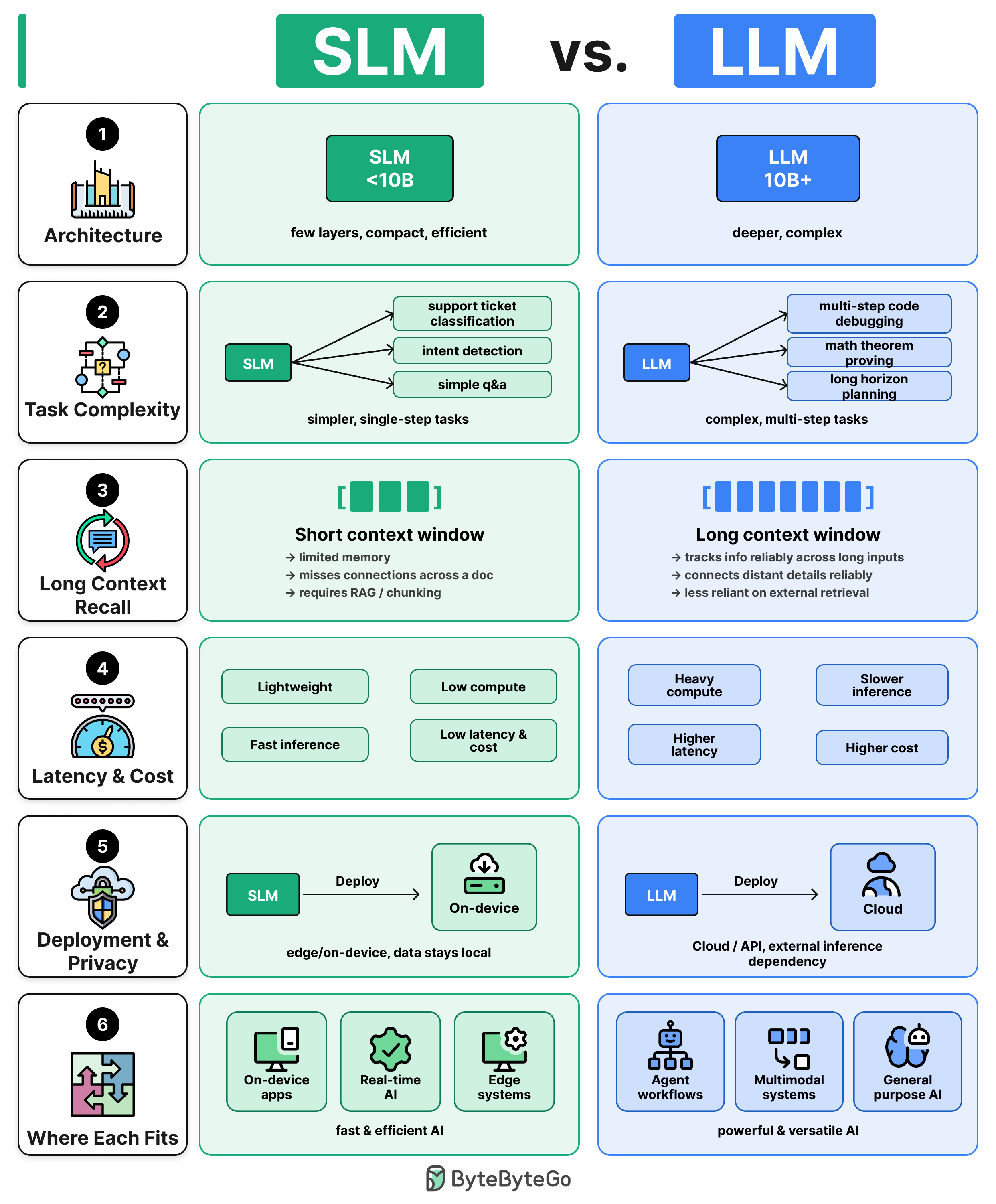
Big models cost more. Small models do less. Here’s how SLMs and LLMs differ across the dimensions that matter in production:
-
Architecture: SLMs are usually under 10B parameters and run on a laptop or phone. LLMs sit at 10B+ with deeper layers and more attention heads, built for broad reasoning across tasks.
-
Task Complexity: SLMs work well on simple tasks but fail on complex multiple reasoning steps. LLMs handle difficult math, multi-step code, and long-horizon planning.
-
Long Context Recall: SLMs lose the thread across long documents or extended conversations. LLMs reliably track and connect information across large inputs.
-
Latency and Cost: SLMs run on consumer hardware with low response times and significantly lower inference costs. LLMs require GPU and carry higher costs per request.
-
Deployment and Privacy: SLMs run on-device or on-premise. LLMs are typically cloud-hosted, which adds data governance complexity.
-
Where each fits:
SLMs: on-device assistants, real-time classification, or privacy-sensitive applications
LLMs: complex reasoning, agent workflows, or broad knowledge tasks.
Are you using SLMs, LLMs, or a hybrid setup in production?
Some tasks need a single agent. Others need a whole team. Knowing the difference is the skill.

Single-agent system: One reasoning LLM that plans, picks a tool, and loops on its own until the task is done. Use a single agent when:
-
the task is a clear, linear sequence
-
one agent can hold the whole problem in its head
-
you want something simple to build and easy to debug
Multi-agent system: An orchestrator that splits a task into subtasks and routes each one to a specialized agent. Use multi-agent when:
-
subtasks can run in parallel
-
one agent writes and another independently verifies the work
-
the problem is too big for one agent to coordinate alone
Single agents are cheaper and easier to build, but they hit a ceiling on complex work.
Multi-agent systems are more capable and more reliable, but they add coordination cost.
Start with a single agent. Move to multi-agent only when context or reliability become the bottleneck.
Over to you: Are you running single-agent or multi-agent systems in production?
-
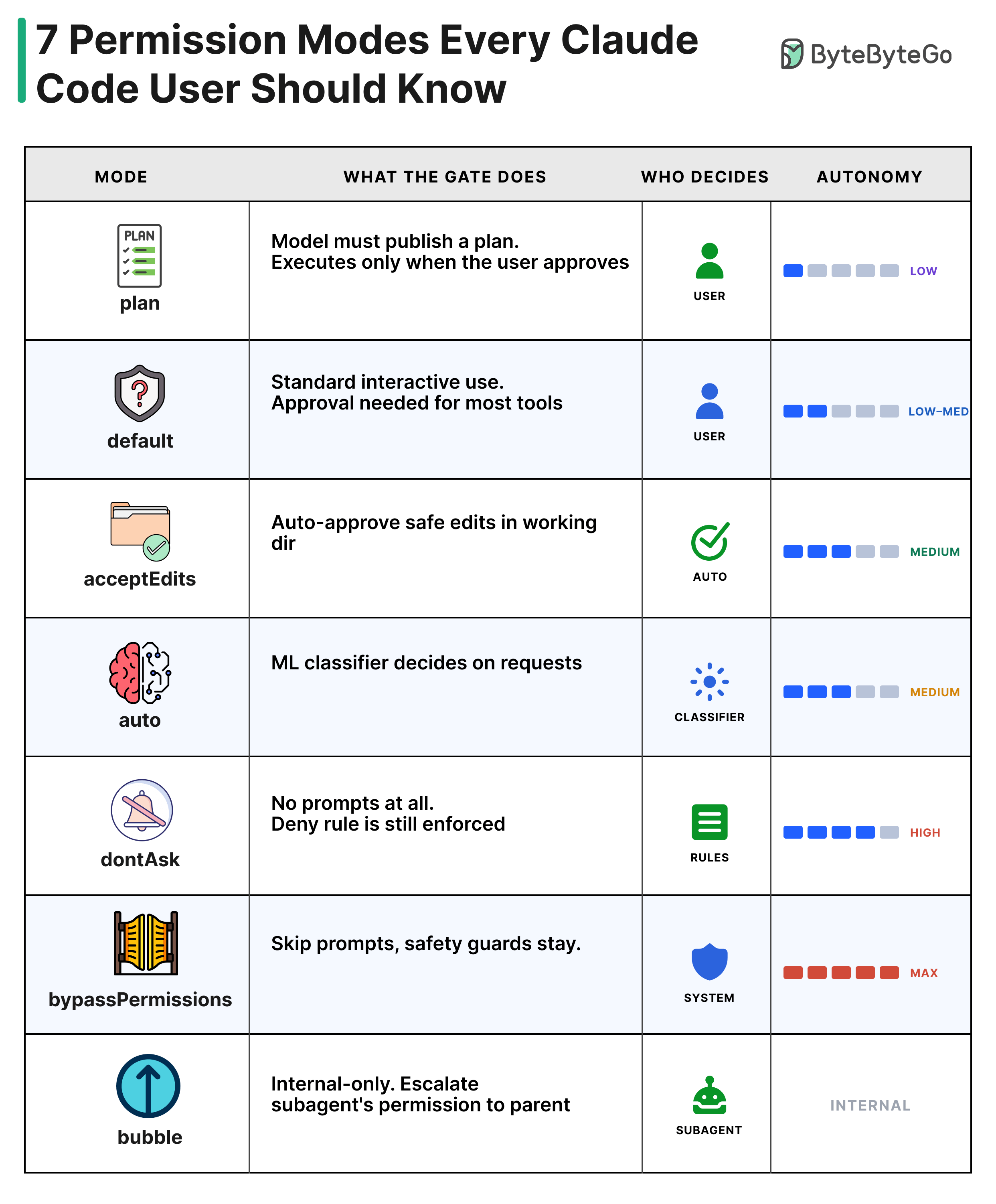
plan: The model drafts a plan. Nothing executes until the user approves.
-
default: Standard interactive use. Most tool calls require user approval.
-
acceptEdits: Edits in the working directory are auto-approved. Other shell commands still prompt.
-
auto: An ML classifier decides on requests that miss the fast path.
-
dontAsk: No prompts shown. Deny rules are still enforced.
-
bypassPermissions: Most prompts are skipped. Safety-critical guards still apply.
-
bubble: A subagent escalates its permission request to the parent.
Only 5 modes are user-selectable. “auto” is gated by a feature flag, and “bubble” is internal.
Over to you: Which mode do you reach for most, and what made you pick it?



