
Most teams optimize models. Few optimize inference. We benchmarked NVIDIA RTX PRO 6000 Blackwell on Akamai Cloud against H100 using real LLM workloads.
At 100 concurrent requests, Blackwell reached 24,240 tokens/sec per server, compared to 1,863 TPS on H100. That’s up to 1.63× higher throughput, with additional gains from FP4 precision.
The difference comes down to architecture. These GPUs run on a globally distributed platform built for real-time, latency-sensitive inference, not centralized batch jobs.
If you’re building agentic systems or high-concurrency AI apps, infrastructure choices matter as much as model selection. See the full setup, methodology, and results. View benchmark results
In 2024, Wise’s deployment system automatically blocked hundreds of releases that would have caused production incidents.
There was no human intervention, but the system routed just 5% of traffic to the new version, watched technical and business metrics for 30 minutes, and rolled back when it detected anomalies. Three years earlier, Wise was deploying with a simpler in-house tool that treated each release as a basic transaction, where the process was essentially to push the code and hope for the best.
This leap was made possible by some interesting engineering decisions that we will learn about in this article.
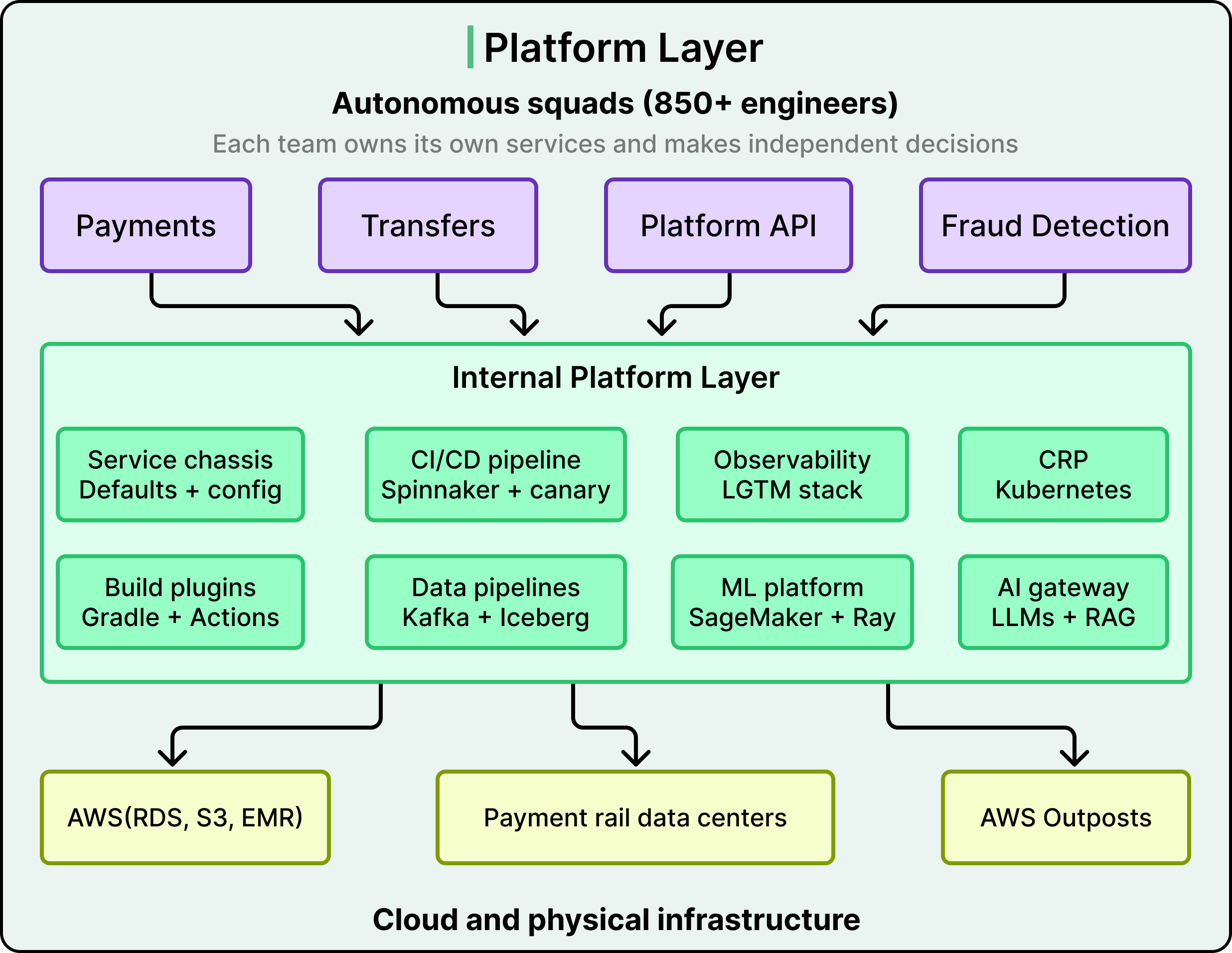
For reference, Wise moves about £36 billion across borders every quarter, with 65% of transfers arriving instantly. One might assume that kind of reliability requires a tightly controlled, top-down engineering organization. However, the opposite is true.
Wise has 850+ engineers organized into autonomous squads, each empowered to make their own technical decisions. The reason this works, and the reason it would collapse without a very specific set of infrastructure investments, is the real engineering story behind Wise.
Behind the product that 15.6 million active customers interact with, there are over 1000 microservices, 700+ Java repositories, 40 web applications, and native iOS and Android apps with hundreds of modules each. What holds all of this together is an internal platform, a set of shared tools, frameworks, and automated systems that make the right engineering choice the easy one.
Disclaimer: This post is based on publicly shared details from the Wise Engineering Team. Please comment if you notice any inaccuracies.
When a system has 1000+ services owned by dozens of independent teams, the most dangerous form of complexity is inconsistency. If every team wires up security, database connections, Kafka consumers, and logging differently, you end up with 1000 slightly different systems that are all hard to debug, upgrade, and secure.
Wise’s answer to this is a microservice chassis framework, an opinionated, pre-configured foundation that every new backend service can start from. The chassis handles security, observability, database communication, Kafka integration, and more, all with recommended defaults so that teams can focus on business logic rather than plumbing.
What makes Wise’s approach distinct is that the chassis is shipped as a versioned artifact rather than a template you fork and modify.
The difference matters. With a template, the service diverges from the standard the moment you create it. With an artifact dependency, updates to the chassis flow downstream when teams bump the version. Security patches, observability improvements, and new defaults reach services through a regular dependency upgrade rather than a manual migration.
This approach also extends to the build pipeline.
Wise built a collection of in-house Gradle plugins, including one that standardizes GitHub Actions workflows. When Wise decided to roll out SLSA (a framework for protecting software supply-chain integrity) across the organization, it became a plugin version update across 700+ Java repositories rather than 700 individual pull requests.
On top of this, a language-agnostic automation service can make complex changes across the codebase at scale and create pull requests for the owning team to review. Dependency upgrades for Java services are now fully automated through this system.
The same standardization mindset shows up on the frontend.
Wise’s web applications are built on CRAB, a Wise-specific abstraction on top of Next.js, split across 40 distinct apps that handle specific product functions. Visual regression testing is handled by Storybook paired with Chromatic, which captures snapshots of React components after each change and highlights visual differences to catch UI bugs before they reach customers.
Standardizing how services are built is only half the problem. The other half is standardizing how they reach production.
Since 2018, Wise has relied on Kubernetes to host its services, originally built with Terraform, JSONNET, and ConcourseCI. That setup supported service-mesh controls through Envoy, PCI-DSS compliance, and frictionless deployments for several years.
But as Wise grew, the original approach could not scale further without becoming a maintenance burden. This led to the Compute Runtime Platform (CRP), a ground-up rebuild of Wise’s Kubernetes infrastructure. Terraform still provisions infrastructure, but the codebase was rewritten from scratch for flexibility. RKE2 now handles cluster bootstrapping, with Rancher managing overall cluster state. Helm replaced JSONNET for better maintainability and upstream compatibility. ArgoCD with custom plugins ensures fully automated provisioning and consistency across environments. The result is that Wise grew from 6 Kubernetes clusters to more than 20 while keeping maintenance manageable.
CRP also brought efficiency improvements:
-
Automated container CPU rightsizing through Vertical Pod Autoscaler is now live in non-production and rolling out to production for non-critical workloads.
-
Horizontal scaling through KEDA optimizes workloads based on daily and weekly traffic patterns.
-
Fully managed sidecar containers like the Envoy proxy simplify deployments for product teams, and Wise’s Envoy-powered service proxy now includes seamless integration and discovery between services.
All of this feeds into Wise’s broader Mission Zero cost optimization goals.
Wise’s deployment strategy has undergone a big shift with the transition from Octopus, their former in-house tool, to Spinnaker. This was more than a tool swap.
Octopus treats deployments as simple transactions, while Spinnaker treats them as orchestrated sequences of events with built-in canary analysis, metric validation, and automatic rollback.
See the diagram below:
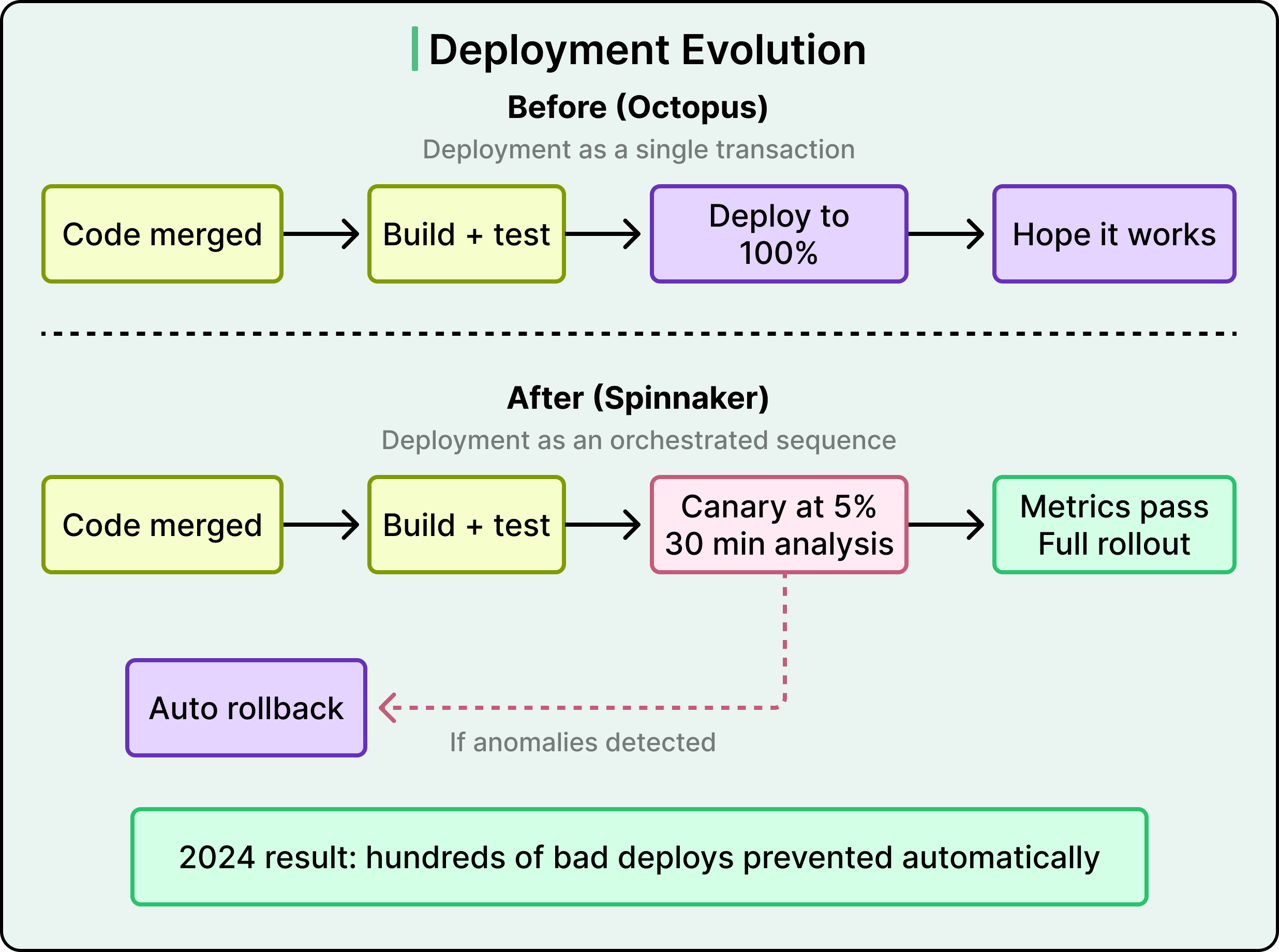
The canary process is simple in concept but powerful in practice.
When a new version of a service is deployed, only 5% of traffic routes to it. Over a 30-minute window, the system analyzes both technical metrics (error rates, latency) and business metrics (transaction success rates, conversion). If it detects significant anomalies, it rolls back automatically. In 2024, this system prevented hundreds of potentially incident-causing deployments and saved thousands of engineering hours. Over half of Wise’s services already run on Spinnaker, with full migration expected by mid-2025.
On the CI side, migrating from CircleCI to GitHub Actions opened new optimization possibilities. By tracking detailed build metrics, Wise discovered that pre-populating caches for frequently used containers could slash build times by 15%. At their scale of 500,000 monthly builds, that translates to over 1,000 hours saved each month. Wise has also been methodically implementing the SLSA framework across build processes, strengthening supply-chain security one language at a time.
Mobile teams have seen similar gains.
-
iOS engineers migrated 250+ Xcode modules from Xcodegen to Tuist and switched from Cocoapods to Swift Package Manager, dropping zero-change build times from 28 seconds to 2 seconds.
-
On Android, the team manages over 300 Gradle modules and has fully moved to Jetpack Compose for UI, adopted Kotlin 2.0 and 2.1, and is exploring Kotlin Multiplatform for cross-platform code sharing.
-
Backend-for-frontend services (BFFs, which are lightweight backends tailored to a specific frontend’s needs) help share logic between Android, iOS, and web teams.
Fast, safe deployments matter even more at Wise than at most companies, because what those services are doing is moving real money through real banking systems around the world.
Wise connects directly to local payment schemes rather than routing through intermediary banks. They went live with InstaPay in the Philippines, were granted access to Zengin (Japan’s instant payments system), and received access to PIX in Brazil. Each of these integrations has different technical requirements, and some demand a physical data center presence in the country.
This creates an infrastructure consistency challenge.
Wise centralizes networking using AWS Transit Gateways, but the details of each integration vary substantially across their UK, Hungary, and Australia data center deployments. The Australian deployment is particularly interesting because it was one of the first deployments of AWS Outpost Servers, which allowed Wise to maintain consistent AWS tooling even inside a physical data center.
The goal is always to keep the infrastructure as uniform as possible so that teams working on payment integrations can focus on the business logic rather than wrestling with environment differences.
Wise also exposes this infrastructure through a public API, allowing banks, financial institutions, and enterprises to integrate cross-border payment services directly. For reference, the Wise Platform supports over 40 currencies and multiple payment routes, with OAuth authentication and built-in compliance features.
All of this money movement generates enormous volumes of data. Wise’s data architecture is built as a pipeline from movement to insight to action, with each layer feeding the next.
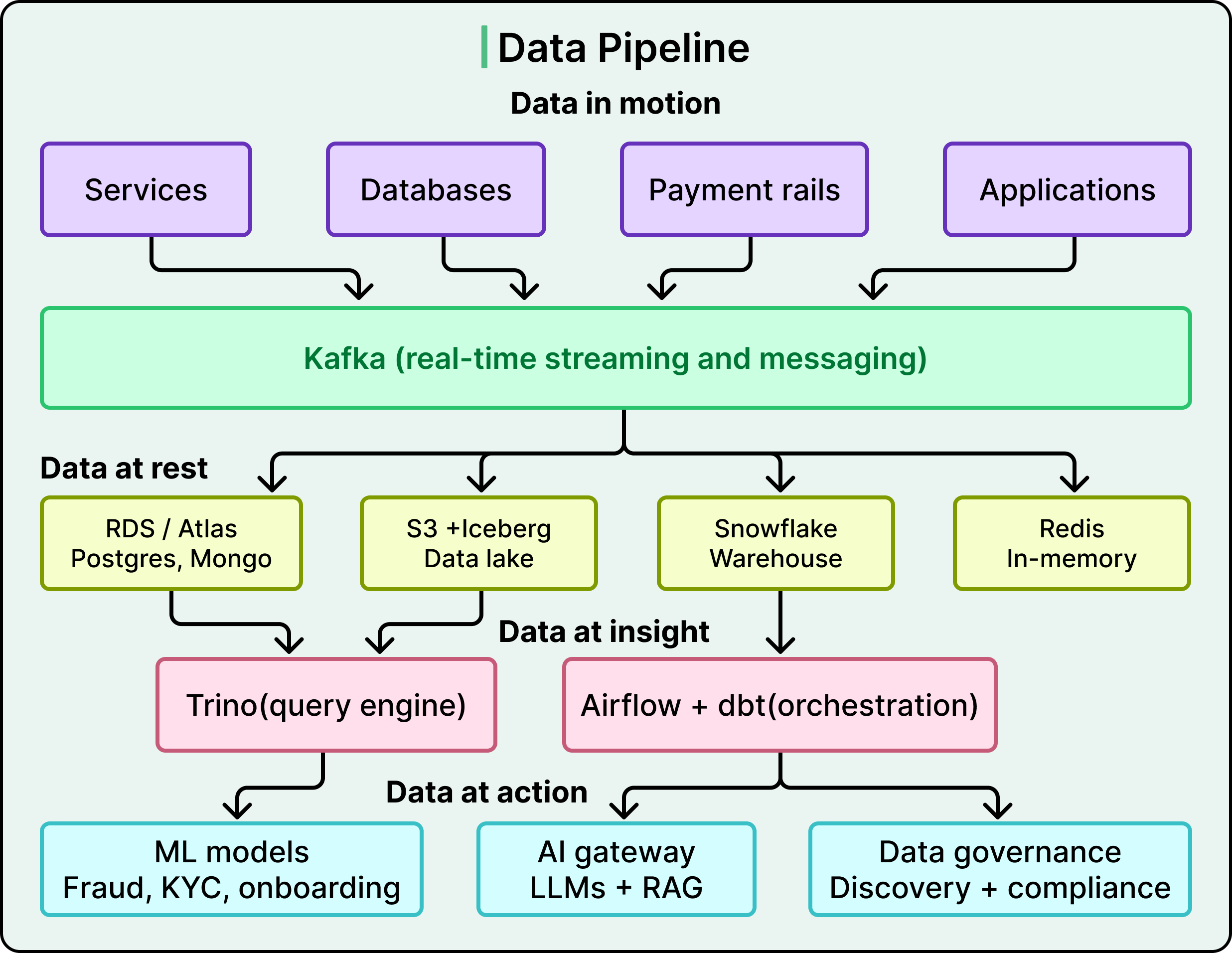
Kafka underpins most of Wise’s real-time data movement, handling asynchronous messaging between services, log collection, and streaming updates for analytics. Their Kafka clusters have grown significantly, with features like rack-aware standby replicas for fault tolerance.
An in-house data movement service funnels information from Kafka and databases into destinations like Snowflake, S3 Parquet, and Apache Iceberg, with automated checks in the configuration process to reduce human error.
A separate Data Archives service now handles over 100 billion records across multiple databases, reducing storage costs and making backups faster.
Wise has migrated most MariaDB and Postgres workloads from self-hosted EC2 instances to Amazon RDS, and is moving from self-hosted MongoDB to MongoDB Atlas. Redis continues to handle in-memory workloads.
For analytics, Wise is building a data lake on Amazon S3 using Apache Iceberg, which allows modifying table structures without rewriting all the data. Trino serves as the federated query engine, letting teams query Iceberg tables, Snowflake, or Kafka streams from one place. A Trino gateway handles workload separation and fault-tolerant queries, while Airflow and dbt-core manage complex data workflows.
Wise has built a comprehensive inventory system and governance portal that tracks where data is stored, who created it, and how it is classified.
Automated data discovery feeds into data deletion, compliance, and audit initiatives. For a regulated financial services company, this is load-bearing infrastructure, and as more engineers join the governance effort, Wise is rolling out stricter policies, enhanced privacy checks, and automated data lifecycle management.
Data scientists work in Amazon SageMaker Studio, with large-scale processing on Spark in EMR and orchestration through Airflow.
SageMaker Feature Store keeps hundreds of features in sync for training and inference, while MLflow tracks experiments, metrics, and model versions. When a model is ready for production, it is deployed through an in-house prediction service built on Ray Serve.
Applications span fraud detection, KYC verification, and customer onboarding, where every millisecond of inference time matters. Automated checks catch data drift and feature inconsistencies before they become serious issues.
Wise has built a secure gateway connecting to multiple LLM providers, including Anthropic (Claude), AWS Bedrock, Google Gemini, and OpenAI. This lets teams experiment with different models without managing separate credentials or compliance checks.
A Python library inspired by LangChain wraps these APIs to speed up prototyping. For cases requiring internal context, a custom Retrieval-Augmented Generation (RAG) service pulls the latest information from various data stores before generating responses, which is useful for summarizing complex documents and automating parts of customer service.
Building all of this is one challenge. Knowing whether it is working is another.
Wise has consolidated its observability stack onto the LGTM stack from Grafana. Loki handles logs, Grafana provides dashboards, Tempo handles traces, and Mimir handles metrics. The migration from Thanos to Mimir was driven by scalability needs, and the metrics stack now ingests roughly 6 million metric samples per second and processes 150 million active series for its largest tenant.
The real value of unification is correlation. When a service fails at 3 AM, developers want to see the error log, the trace showing which downstream call failed, and the metric spike that triggered the alert, all in one place and linked together. Running separate tools for each of those signals means context-switching during an incident, which costs time when time matters most.
Wise has also implemented dedicated observability clusters within its Compute Runtime Platform, separating monitoring infrastructure from production workloads so that a spike in monitoring load cannot affect the services being monitored. They are pilot testing Grafana Pyroscope for profiling select services, and have adopted Temporal as a workflow engine to automate database switchovers and recovery tests, keeping downtime minimal while staying compliant with strict resilience regulations.
Cost optimization is an ongoing task. Wise has invested in reducing operational costs and improving resource utilization across the observability stack, tying these efforts to their broader Mission Zero initiative.
A pattern runs through every layer of Wise’s tech stack.
-
At the frontend, the chassis and CRAB framework standardize how applications are built.
-
At the deployment layer, Spinnaker and automated canary analysis standardize how code reaches production.
-
At the infrastructure layer, CRP and Kubernetes absorb the complexity of hosting services.
-
At the data layer, shared pipelines and governance tools standardize how information flows.
-
At the observability layer, the LGTM stack standardizes how teams understand what is happening.
The common thread is that Wise treats its internal infrastructure as a product. The customers are the 850+ engineers.
The features are faster builds, safer deployments, easier service creation, and unified monitoring. And just like any product, the platform keeps evolving. CircleCI gives way to GitHub Actions, Octopus gives way to Spinnaker, Thanos gives way to Mimir, because the needs of those internal customers keep changing.
The trade-off is that this level of platform investment requires dedicated teams, carries significant migration cost, and only starts to pay off past a certain organizational size.
References:



