
Datadog analyzed tens of thousands of production applications to reveal where risk is actually showing up and what it means for teams handling security today. Download the full report to dive into the key findings, including:
-
Why 87% of orgs have exploitable vulnerabilities in production, and how end-of-life runtimes and outdated dependencies are quietly driving that number
-
How to cut alert noise by 80% by focusing only on vulnerabilities that pose real business risk
-
The hidden dangers of day-one library, AMI, and Docker image updates, and how supply chain attacks exploit them
In December 2024, an AI lab called DeepSeek released a 671-billion-parameter language model along with a technical report describing exactly how they built it. Six months later, a different team called Moonshot AI used that report as a starting point. They scaled the design to a trillion parameters, ran into a training instability problem that emerged at that scale, invented a new optimizer to solve it, and shipped their own model. Eight months after that, a third team called Zhipu AI integrated a different DeepSeek innovation into their architecture and contributed a new training framework of their own.
These three teams work for different organizations. However, they were indirectly collaborating in public, through model releases where each company was learning from what its predecessors had done before. This has been made possible by the rise of open-weight models, where even competitors get to learn from each other. The pace of that kind of collaboration has changed over the past eighteen months, and the reasons trace back to the architecture and training choices these teams made in the open.
In this article, we will look at how open-weight models have transformed the AI landscape.
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
Every modern large language model has two important things behind it:
-
The first is the trained parameters, which are the numbers, often hundreds of billions of them, that the model learned during training. The parameters are what make the model “know” things.
-
The second is everything that produced those parameters, including the training data and the training code.
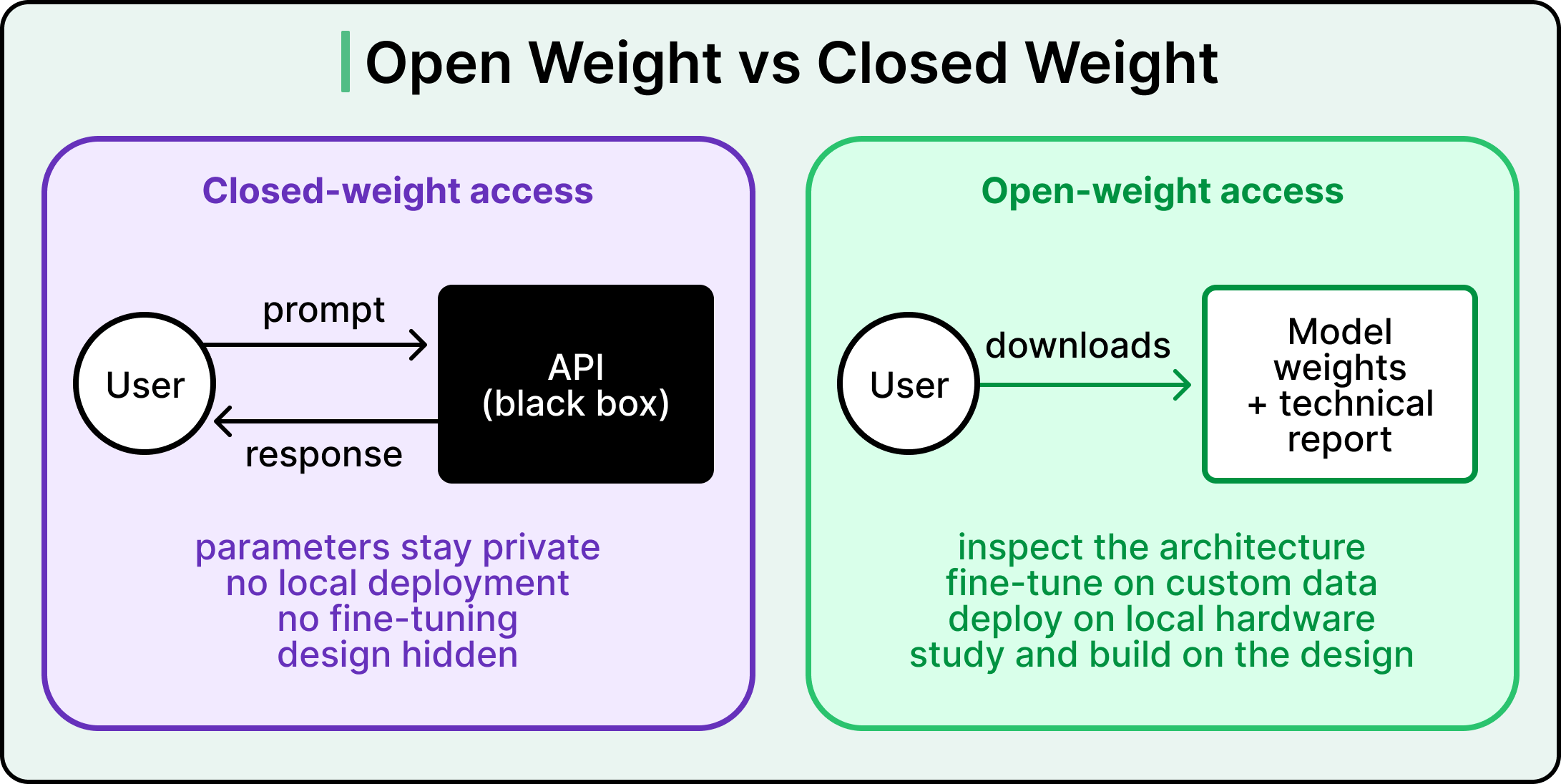
A closed-weight model is one that the company keeps behind an API. The user sends some text to the official API endpoint, the company’s servers run the model on their hardware, and a response comes back. The parameters stay with the organization, and running the model on personal hardware or adjusting it for a specific task remains out of reach.
An open-weight model is one where the company has published the trained parameters. Anyone can download them, run the model on their own hardware, and adjust it for their own data. The training data and the full training code, however, usually stay private.
The term is “open weight” rather than “open source” for this reason.
In traditional software, “open source” means the full source code is available to inspect and reproduce. Most AI models marketed as open source are actually open weight, where the trained model is public, while the process that produced it remains closed. This distinction matters because the published weights, paired with detailed technical reports, are what allow other teams to study a design and build on top of it.
Different open-weight models also use different licenses, ranging from very permissive ones like MIT and Apache 2.0 to custom licenses with specific commercial restrictions, so the practical freedoms vary across the ecosystem.
See the diagram below that shows the difference between accessing a closed-weight model and an open-weight model:
Every major open-weight LLM released at the frontier in 2025 and 2026 shares the same architectural skeleton. It is called a Mixture-of-Experts transformer, or MoE for short.
Modern LLMs are built from stacked “blocks.” Each block has two main parts, an attention layer that figures out which previous words matter for the next one, and a feed-forward layer that does the actual computation.
In a regular (”dense”) model, every parameter activates for every word the model processes. Adding more parameters to make a smarter model means the cost of running it scales linearly with that count. With hundreds of billions of parameters, this becomes impractical.
MoE solves this by replacing the single feed-forward layer in each block with several smaller “expert” sub-networks, plus a small routing component that picks which experts to use for each word. The model can store knowledge across many experts while only computing a few of them per word.
This is why two numbers matter for every MoE model:
-
The first is total parameters, which represent the model’s full memory footprint and knowledge capacity.
-
The second is the active parameters, which represent how much of the model actually computes per word. Active parameters drive inference speed and per-query cost.
DeepSeek V3, for example, has 671 billion total parameters but only 37 billion active per word. Kimi K2 has a trillion total, but 32 billion active. Qwen3 has 235 billion total and 22 billion active. When comparing the cost of running these models, the active counts are what matter, rather than the totals. A trillion-parameter model and a 235-billion-parameter model can cost roughly the same per query if their active counts are similar.
See the diagram below that shows how an MoE block works:
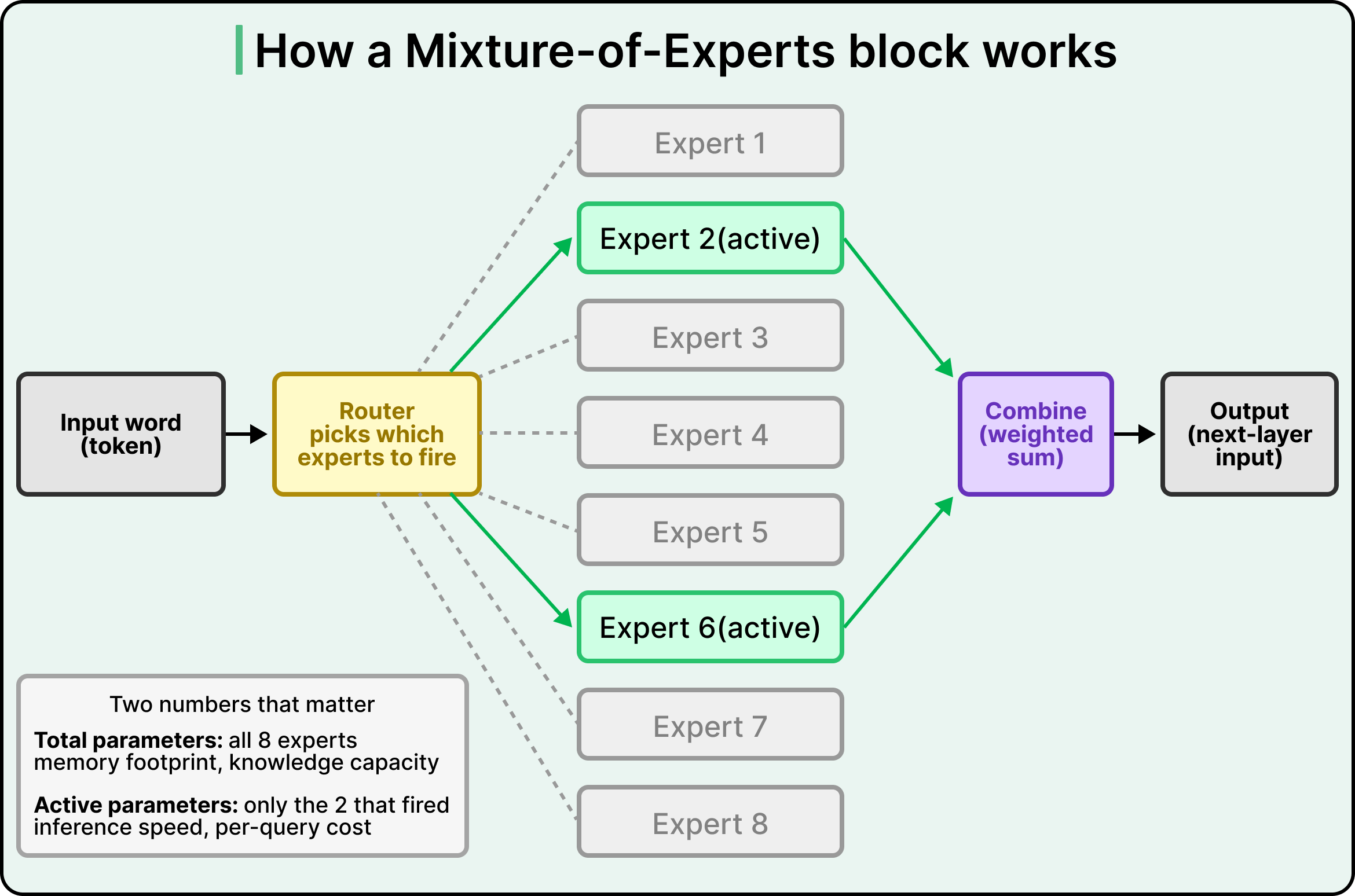
Beginners often assume that experts in MoE specialize by topic, with a math expert, a code expert, and so on. The reality differs from that picture. The router picks experts per word, rather than per question, and the patterns experts specialize in are mostly outside human interpretation. The routing is fine-grained, and a single sentence will pass through many different combinations of experts as it generates.
The MoE architecture explains why every frontier open-weight team is using roughly the same approach. The interesting differences lie in the design choices teams make inside that design approach, and three places are where those choices show up most clearly.

Every organization is exploring how to adopt AI agents or MCP servers, but how many of them are in production?
And if they aren’t in production, how likely is it that authentication, access control, and agentic identity concerns are the reason?
Watch this on-demand webinar from Descope to learn:
-
Real-world MCP and agentic AI use cases
-
Identity challenges that prevent production-readiness
-
Actionable tips to build secure, scalable AI agents and MCP servers
The first place is in how teams handle attention.
Every time the model generates a word, it looks back at every previous word in the conversation to figure out what comes next. To avoid recomputing this lookback at every step, the model caches information from earlier words. This cache is called the KV-cache, short for “keys and values,” and it grows as the conversation grows. For long conversations, the KV-cache becomes the main memory bottleneck.
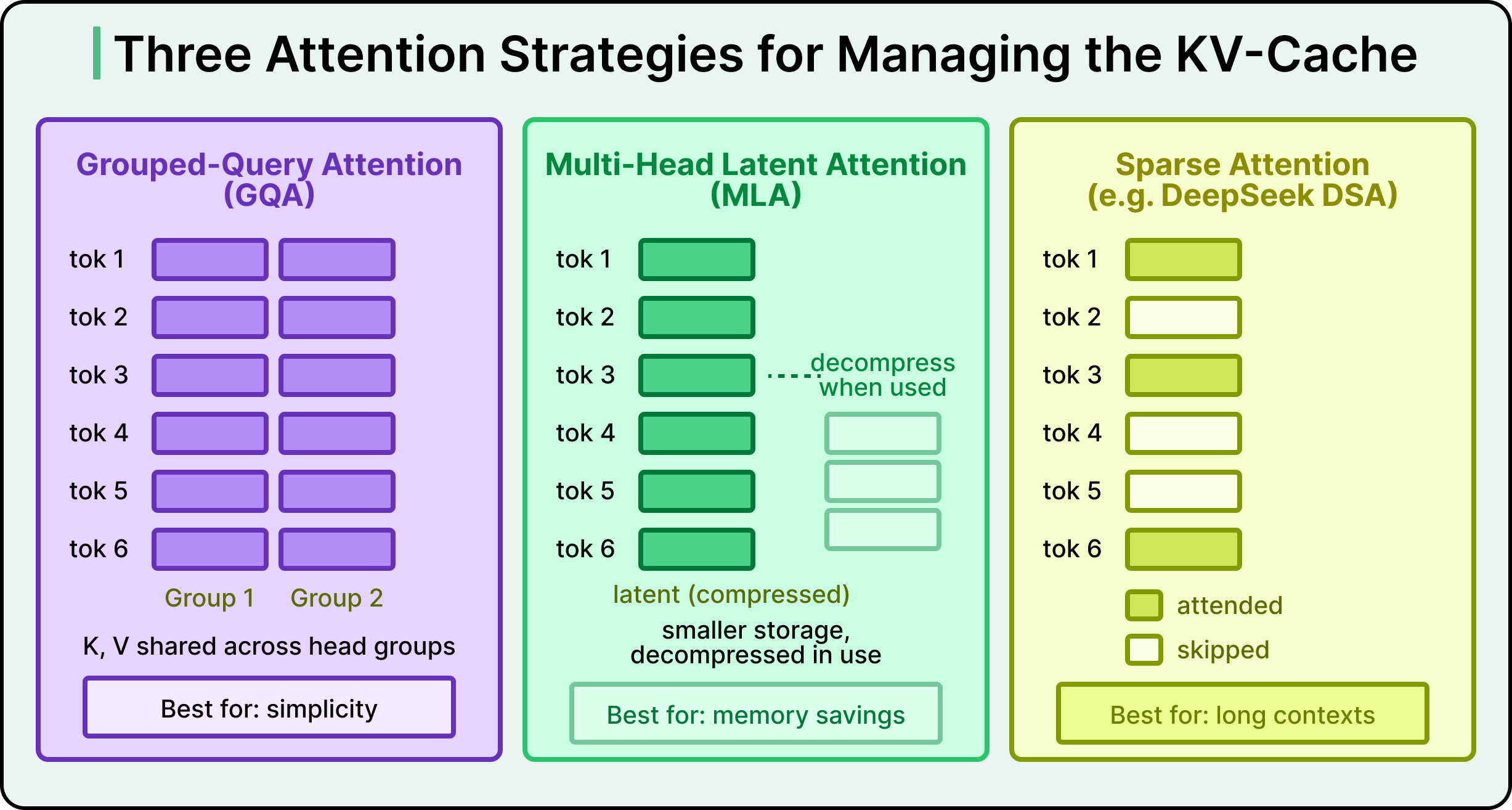
Three different strategies have emerged for managing it.
-
Grouped-Query Attention (GQA): Shares cached information across groups of attention heads, which reduces memory usage with a relatively simple implementation. Qwen3 and Llama 4 both use GQA. It is the easiest of the three to engineer and the most widely adopted across the industry.
-
Multi-Head Latent Attention (MLA): Compresses the cached information into a smaller latent representation before storing it, then decompresses when the model needs to use it. MLA was introduced by DeepSeek and adopted by Kimi K2. It saves more memory than GQA, while adding computational work for the compression and decompression steps.
-
Sparse Attention: Selects only the most relevant previous words to attend to, instead of attending to every one. DeepSeek introduced their version, called DeepSeek Sparse Attention, in V3.2. Zhipu AI’s GLM-5 adopted it shortly after. Sparse attention is most useful when the context is very long, where attending to everything becomes expensive, although it requires careful design to avoid skipping important tokens.
Each strategy is a rational choice depending on what the team is optimizing for, whether that is engineering simplicity, memory efficiency, or context length.
See the diagram below that shows the three attention strategies side by side:
The second point where the teams diverge is in how aggressively they use the MoE pattern.
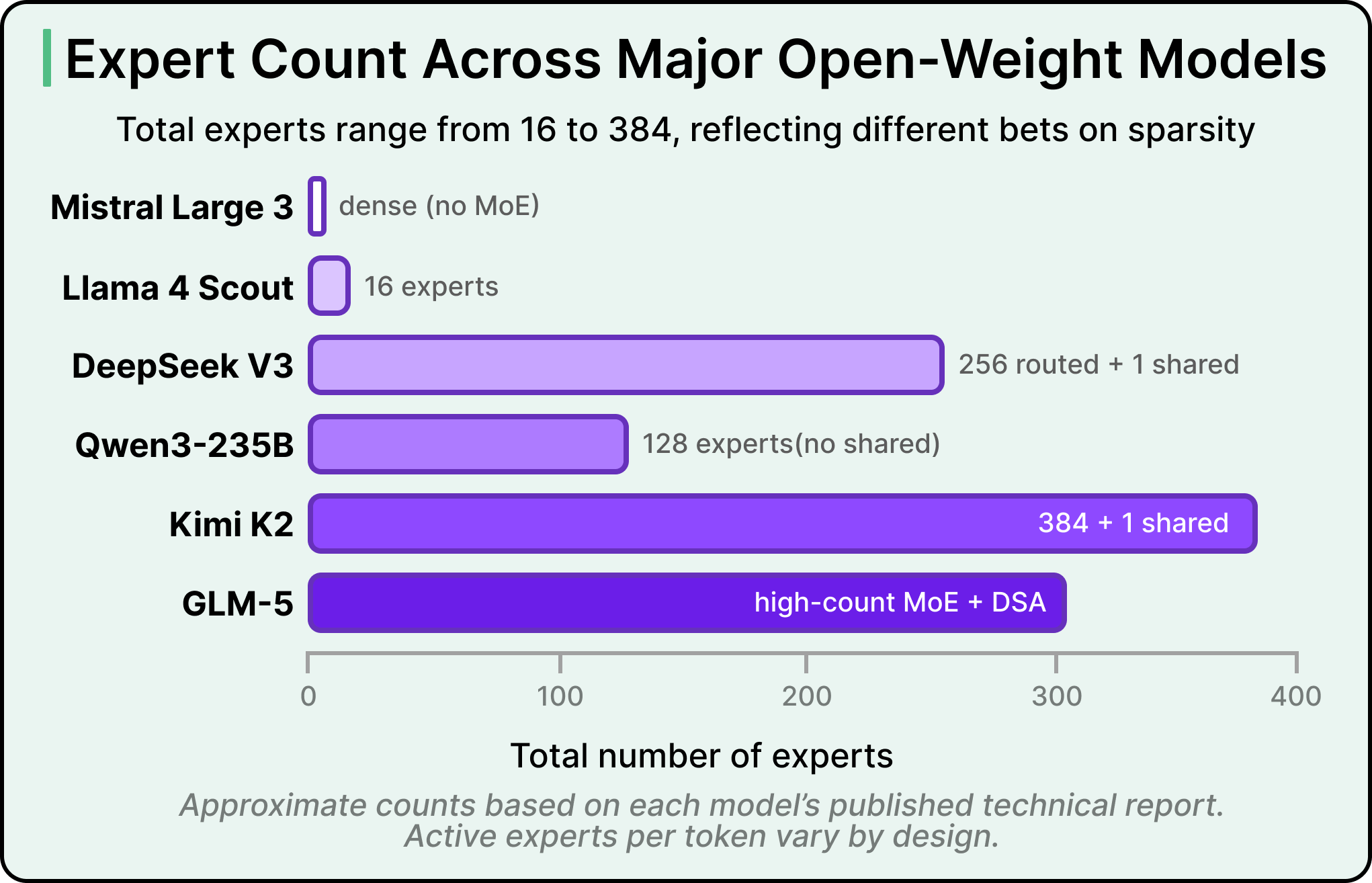
Across the major open-weight models released in 2025 and 2026, the number of experts ranges from 16 to 384. That wider spread reflects a real disagreement about how far to push sparsity.
At a fixed compute budget, increasing the number of experts can lower training and validation loss, meaning the model learns better from the same amount of compute. The tradeoff is memory. More total experts mean more total parameters that need to live in memory, even if only a few of them fire per word. Kimi K2’s trillion total parameters require a multi-GPU cluster regardless of how few experts activate per token, while Llama 4 Scout’s 109 billion total parameters fit on a single high-memory server. Both belong to the same architectural family, although the deployment realities differ significantly.
A separate disagreement exists around whether to include a “shared expert” that processes every word and provides a baseline capability floor. DeepSeek V3, Llama 4, and Kimi K2 include one. Qwen3 dropped it after using one in their previous Qwen2.5-MoE, and their technical report stays silent on why. Consensus in the field on shared experts remains elusive, which is worth flagging because beginners often assume technical questions in well-resourced labs are settled. Many of them remain open.
Llama 4 takes a particularly distinctive approach. Rather than making every layer in the model an MoE layer, Llama 4 alternates between dense and MoE layers. It also routes each word to only one routed expert, plus the shared one, instead of eight as in DeepSeek V3. The result is fewer active experts per word, with each expert being larger, which represents a different architectural bet from the rest of the field.
See the diagram below that shows how the expert count varies across these models:
The third point at which teams diverge is in training.
Architecture is one-half of how a model behaves. Training is the other half, and lately it has become where the more meaningful differences live.
Pre-training is the part where the model learns to predict the next word across trillions of tokens of text. Pre-training gives the model its base knowledge of language and the world. The scale varies between teams, with DeepSeek V3 trained on 14.8 trillion tokens and Qwen3 trained on up to 36 trillion. The general approach, however, remains similar across teams.
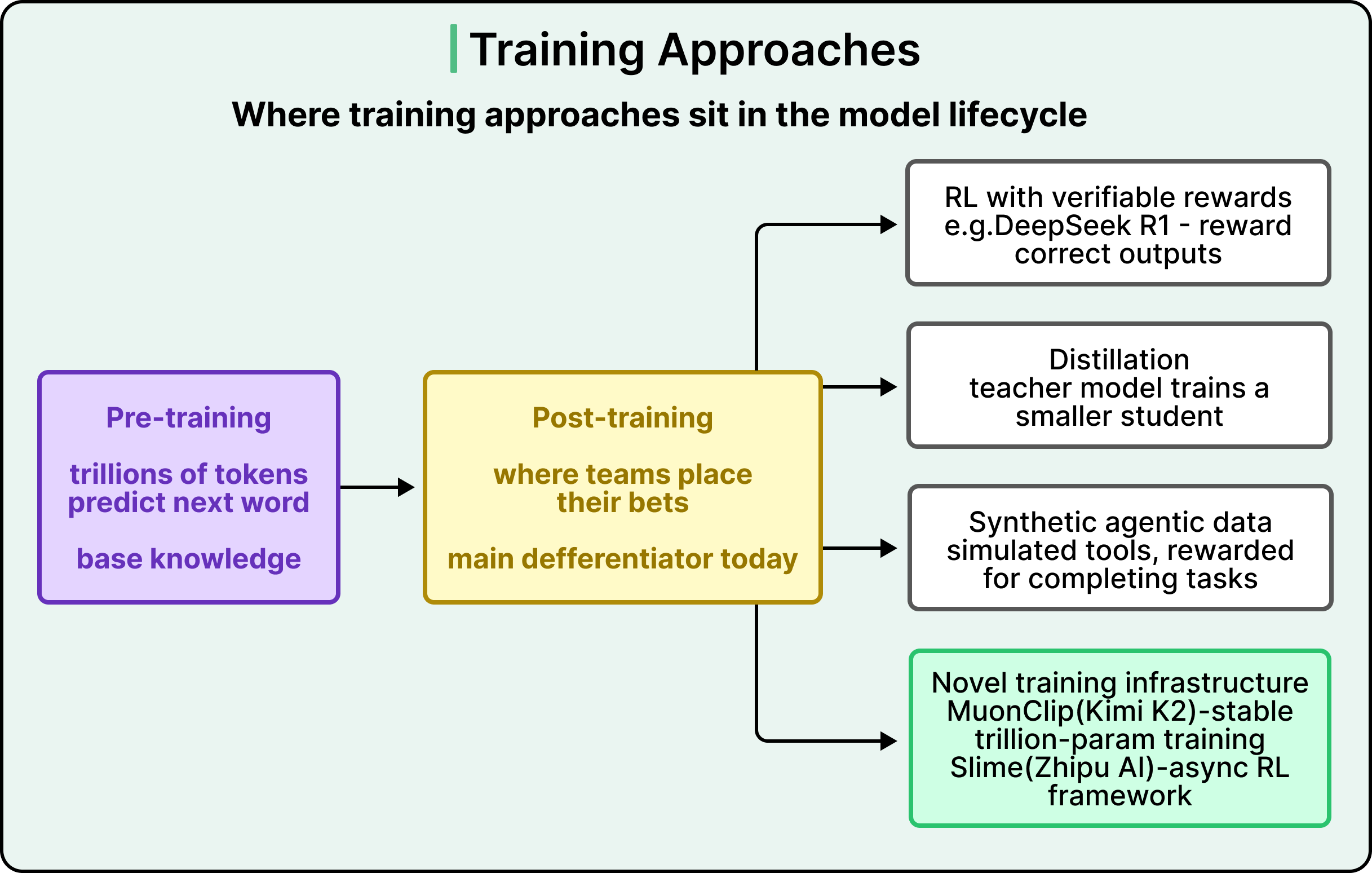
Post-training is everything that happens after, and post-training is where models now diverge the most. Three techniques deserve attention here.
-
The first is reinforcement learning with verifiable rewards. The model produces an output, and the output gets checked for objective correctness. Did the code compile? Did the math answer come out right? The model is rewarded for correct outputs and adjusted away from wrong ones. This was the breakthrough behind DeepSeek R1, and elements of it have been adopted across the open-weight ecosystem.
-
The second is distillation. A very large “teacher” model is trained, and its outputs are then used to train smaller “student” models. Llama 4 was co-distilled from a 2-trillion-parameter teacher called Behemoth during pre-training itself. Qwen3 distills from its flagship model down to smaller members of the family.
-
The third is synthetic agentic data. Teams build simulated environments loaded with real tools like APIs, shells, and databases, and reward the model for completing tasks in those environments. Kimi K2’s technical report describes a large-scale pipeline that generates tool-use demonstrations across simulated and real-world environments.
Beyond these techniques, the training infrastructure itself has become a meaningful contribution. Two examples from the recent ecosystem stand out.
-
MuonClip: Kimi K2’s team developed this optimizer because their training run was hitting instability at the trillion-parameter scale. With MuonClip, they trained on 15.5 trillion tokens without a single loss spike.
-
Slime: Zhipu AI built this asynchronous reinforcement learning framework to improve training throughput, which allows more training iterations within the same compute budget.
Both contributions may end up being more reusable across the ecosystem than any specific architectural choice. Architecture is converging while training is now where teams place their different bets.
See the diagram below that shows where these training approaches sit in the overall pipeline:
A pattern runs through all three of these approaches when looked at together.
-
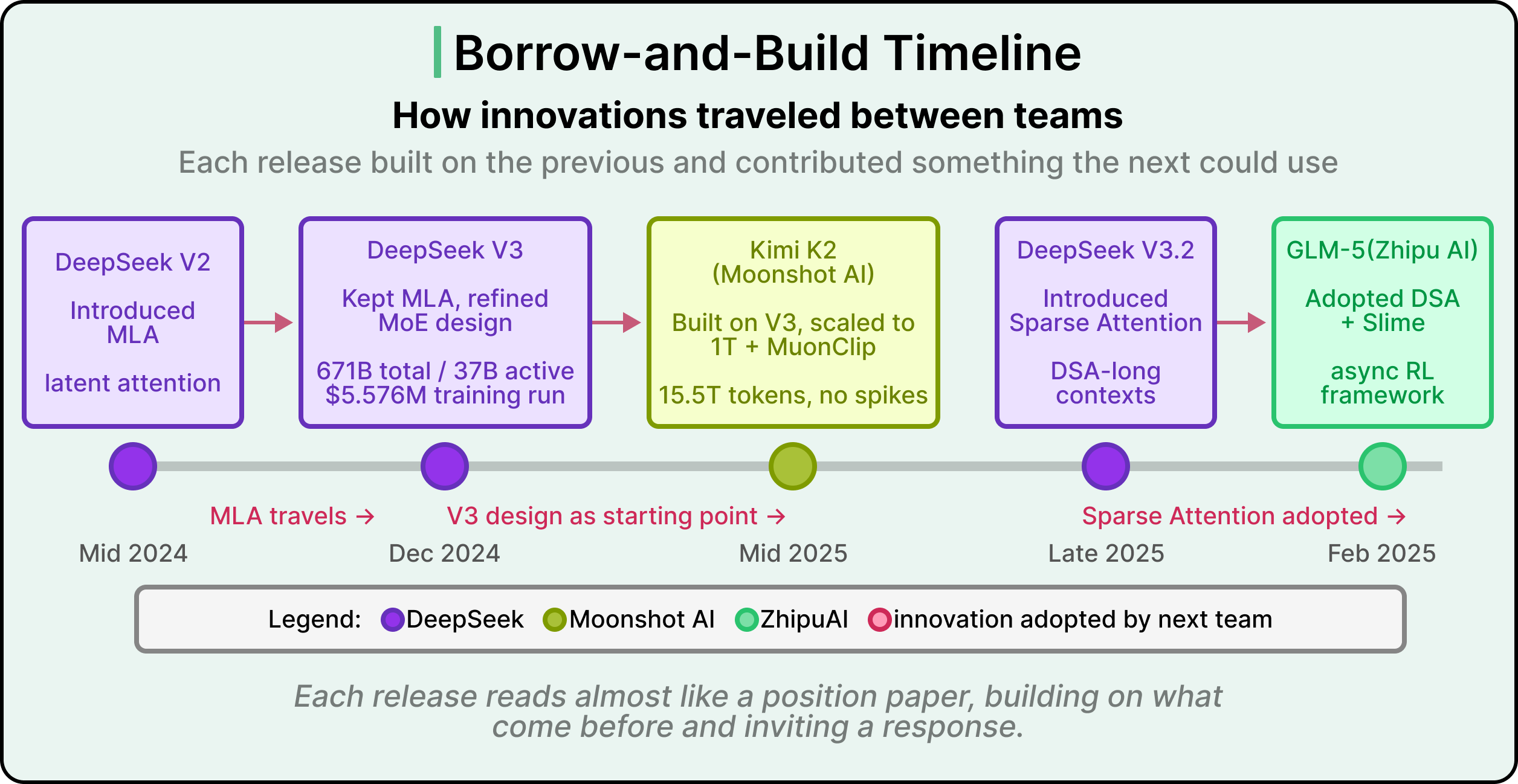
DeepSeek V2 introduced MLA.
-
DeepSeek V3 kept MLA and refined the MoE design, training the resulting model for approximately 5.5 million dollars on 14.8 trillion tokens.
-
Moonshot AI’s Kimi K2 used DeepSeek V3 as a starting point, scaled the design to a trillion parameters, and contributed MuonClip when the scale-up surfaced new training instability.
-
DeepSeek V3.2 introduced sparse attention.
-
Zhipu AI’s GLM-5 adopted that sparse attention approach and contributed Slime, a new framework for the post-training phase.
Each team built on the previous team’s published innovations, and each added something the next team could build on in turn. These innovations all depend on published weights and detailed technical reports.
See the diagram below that shows how innovations have traveled between teams over the past eighteen months:
This is an observation about the open-weight ecosystem rather than a verdict that open-weight is “winning” or that closed-weight teams have fallen behind. Closed-weight teams are doing different work, optimized for different things, and many of their innovations stay private by choice. The open-weight ecosystem, however, has produced a kind of technical conversation that ran on a smaller scale before.
The specific models covered here will likely be overtaken in months. The framework for reading them, however, will probably hold.
Modern open-weight LLMs share a common skeleton, the MoE transformer, where total parameters and active parameters represent two different costs. Within that skeleton, teams place distinctive bets in three places:
-
The first is the attention strategy, choosing between GQA, MLA, or sparse attention.
-
The second is how aggressively to use sparsity, which ranges across the field from 16 experts to 384.
-
The third is the post-training approach, drawing from reinforcement learning, distillation, synthetic agentic data, or novel training infrastructure.
The license under which a model is released determines what teams and individuals can actually do with it, and “open weight” remains technically narrower than the traditional notion of open source.
The most interesting development in this period of AI engineering is the innovations that open-weight models are inspiring through their published designs
References



