

[ad_1]
Most AI agents work in demos — but fail in production. Learn how to build durable, enterprise-ready AI agents with open-source frameworks using Orkes Agentspan and Conductor. This whitepaper explores how to orchestrate long-running, fault-tolerant agent workflows with built-in governance, observability, retries, and human approvals. See how Agentspan compares to LangGraph, CrewAI, and AutoGen for real-world enterprise AI systems. If you’re building AI workflows that need reliability, scale, and control, this guide shows the architecture patterns that make production-grade agents possible.
A single season of a Netflix show can generate over 2,000 hours of raw footage. That’s 216 million frames.
When a film editor needs to find the exact moment where a specific character says a specific line in a specific location, they’re facing one of the hardest search problems in all of software engineering. And the solution has surprisingly little to do with building a better AI model. The real challenge, it turns out, is plumbing.
Netflix editorial teams used to lose days searching for specific moments buried in raw production footage. For example, a director might need every shot of a character in a particular setting. A marketing team might want the five most visually striking action sequences across an entire franchise. Finding these moments meant hours of manual scrubbing through thousands of hours of material. Creative momentum would stall in situations like this.
The team that solved this problem built something that looks simple from the outside, just a search bar. But underneath it sits a three-layer pipeline that orchestrates an ensemble of AI models, fuses their outputs across a shared timeline, and serves hybrid text-and-vector queries at sub-second latency.
When those multiple AI models run over the same footage, the baseline of 216 million frames explodes into billions of multi-layered data points. Storing, aligning, and intersecting that volume while maintaining sub-second query performance goes well beyond what any traditional database can handle alone.
In this article, we will understand how Netflix built this system and the challenges it faced.
Disclaimer: This post is based on publicly shared details from the Netflix Engineering Team. Please comment if you notice any inaccuracies.
Why would Netflix run multiple AI models over the same footage instead of relying on one powerful model that does everything?
This is because specialized models consistently outperform generalists at their particular task. A model trained specifically for face recognition will identify characters more accurately than a general-purpose vision model. A model tuned for scene classification will map environments more precisely. A dialogue transcription model will capture speech more reliably.
Therefore, Netflix runs an ensemble of specialists. For example, one model recognizes characters. Another classifies scenes and environments. A third transcribes dialogue. A fourth detects objects. Each model is excellent at its job, but each one also produces a fundamentally different kind of output.
For reference, a character recognition model might output a text label like “Joey.” In contrast, a scene classification model produces a 512-dimensional vector embedding, which is basically a list of numbers that represents the mathematical “meaning” of a scene in a way that machines can compare. On the other hand, a dialogue model outputs timestamped transcript text. These are entirely different data types, and they require different search strategies to query.
See the diagram below:
The format problem is only half the challenge. Each model also slices the video into different, overlapping time intervals. The character model might detect “Joey” from seconds 2 through 8. The scene model might detect “kitchen” from seconds 4 through 9. There is no shared timeline across models. The intervals overlap, but they don’t align.
So, if we think about it, the engineering team had to solve one core challenge.
How do you take all these different outputs, produced at different time resolutions, in different formats, and merge them into one searchable index?
Netflix is also exploring a fundamentally different approach to this problem through a single unified foundation model called MediaFM that handles audio, video, and text together. Whether the future favors specialized ensembles or unified generalists remains an open question in multimodal AI. But for now, the production system relies on a three-stage pipeline that treats each concern separately.
The transition from raw model output to searchable intelligence follows a decoupled, three-stage process.
Each stage handles one concern and one concern only. This separation is the architectural backbone of the entire system, and it exists because coupling any two stages would create bottlenecks at Netflix’s scale.
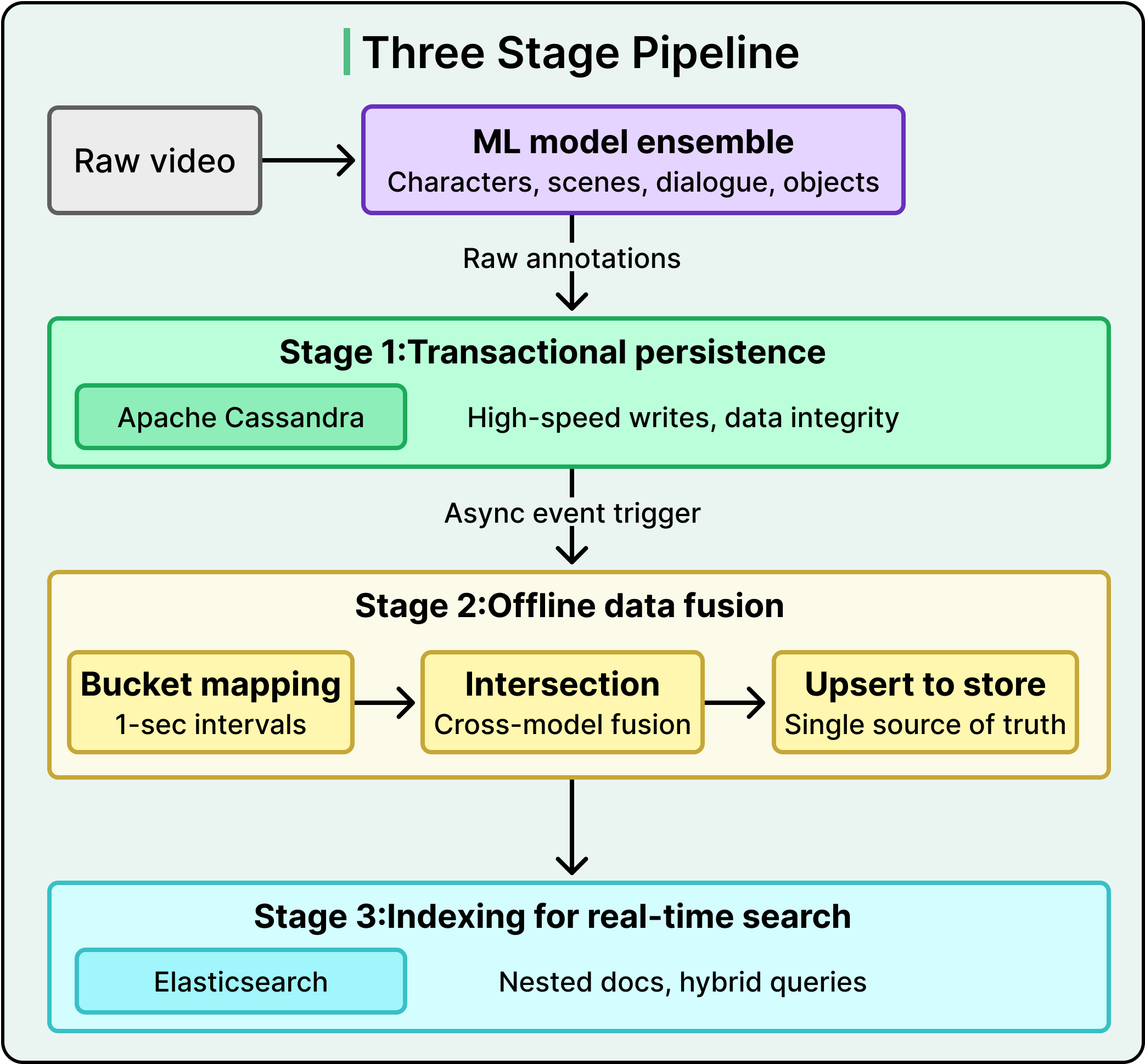
Raw annotations from all models are ingested and stored in Apache Cassandra, a distributed database optimized for high-speed write throughput. This stage strictly prioritizes data integrity. Every piece of model output gets safely captured, with zero transformation. The system stores it exactly as the model produced it.
Why keep this stage separate from everything that follows?
It is because if the system tried to process or fuse data during ingestion, the heavy computation would slow down real-time intake. Decoupling ensures that no matter how many models are running or how much data they produce, the ingestion layer keeps up.
Once raw data is safely persisted, an event triggers an asynchronous processing job. This offline fusion layer is the architectural heart of the system. It handles the heavy computational work outside the real-time path, so complex data intersections never interfere with ongoing ingestion.
The key technique here is temporal bucketing.
See the diagram below:
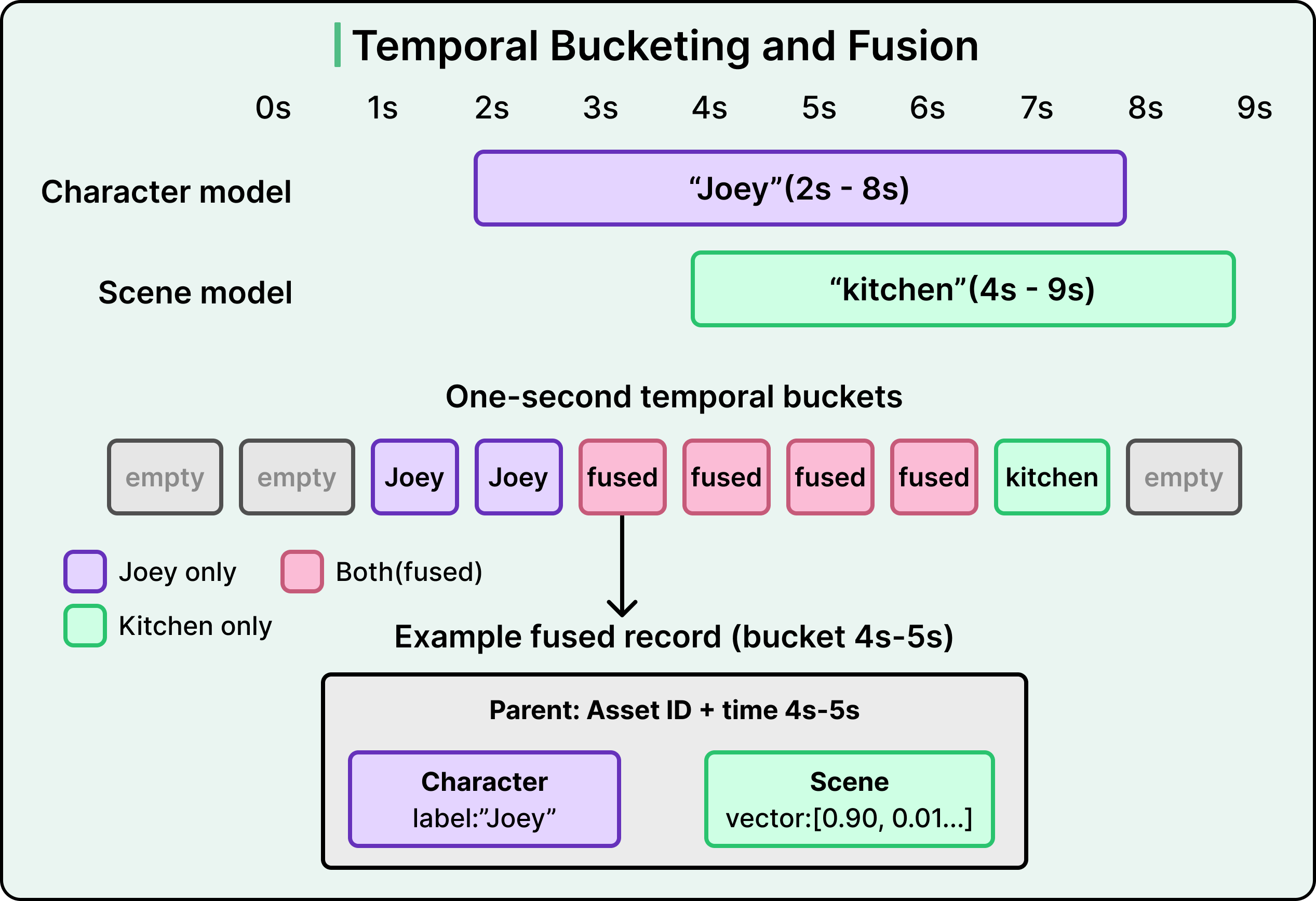
The pipeline normalizes all model outputs by mapping them into fixed one-second intervals. This unfolds in three steps:
-
First is bucket mapping. Continuous detections get segmented into discrete one-second intervals. If the character model detects “Joey” from seconds 2 through 8, the pipeline maps that continuous span into seven distinct one-second buckets.
-
Second is annotation intersection. When multiple models produce annotations for the same one-second bucket, the system fuses them into a single comprehensive record. If “Joey” and “kitchen” both appear in the bucket covering second 4 to second 5, they get merged into one record that says “Joey is in a kitchen during this specific second of footage.”
-
Third is optimized persistence. These enriched, fused records are written back to Cassandra as distinct entities. The result is a second-by-second index of multi-modal intersections, precisely associating every fused annotation with its source video asset.
One important detail makes this process incremental.
The pipeline uses upsert operations, meaning it will update an existing record if one is found or insert a new one if it isn’t, using a composite key that combines the asset ID and the time bucket as the unique identifier.
If a temporal bucket already exists for a specific second of video, perhaps populated by an earlier model run, the system updates the existing record rather than creating a duplicate. This establishes a single source of truth for every second of footage, and it means the system gracefully handles new models being added over time.
The one-second bucket size is itself a meaningful design decision.
Smaller buckets mean finer temporal precision but dramatically more records. At one-second resolution, a 2,000-hour archive produces 7.2 million buckets, each potentially containing multiple annotations from multiple models. Netflix chose one second as the balance point between precision and manageability.
Once the enriched temporal buckets are persisted, a subsequent event triggers their ingestion into Elasticsearch, the system’s query engine.
Each temporal bucket is structured as a nested document:
-
The parent level captures the overarching asset context, including the asset ID, the movie ID, and the time interval.
-
Child documents within it house the specific multi-modal annotations like character data, scene embeddings, and dialogue text. This hierarchical structure is what makes cross-annotation queries possible.
When a user searches for “Joey in the kitchen,” Elasticsearch can match the character annotation and the scene annotation within the same parent bucket in a single query.
With a fused, indexed timeline in place, the system is ready for the part users actually see.
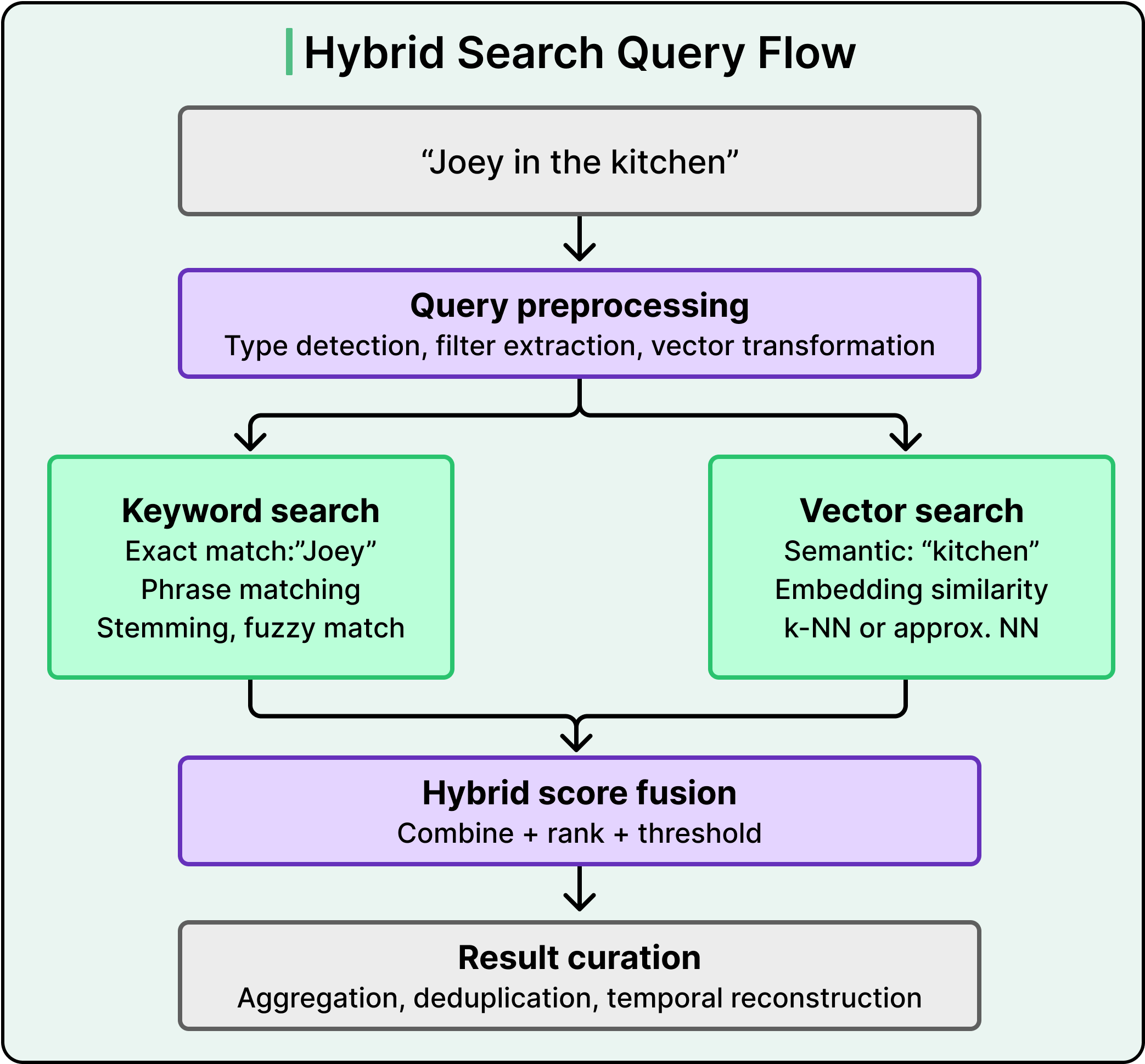
When a query arrives, the system runs a three-step preprocessing phase before touching the index.
-
Query type detection dynamically categorizes the request to route it down the most efficient retrieval path.
-
Filter extraction isolates semantic constraints like character names or environmental contexts to narrow the candidate pool before expensive computation begins
-
Lastly, vector transformation converts the raw text query into high-dimensional, model-specific embeddings for semantic matching.
The system then compiles this structured plan into an optimized Elasticsearch query and executes it against the pre-fused temporal buckets.
A query like “Joey in the kitchen” requires two fundamentally different kinds of matching.
“Joey” is a proper noun that demands exact keyword matching. “Kitchen” is a semantic concept that benefits from vector similarity search, where the system compares the mathematical distance between the query embedding and scene embeddings stored in the index.
A keyword search alone would miss scenes labeled with related terms. Also, vector search alone would struggle with proper nouns and exact phrases. The combination of both is called hybrid search, and it consistently outperforms either approach in isolation.
Netflix gives users fine-grained control over this hybrid engine.
They can toggle between exact k-Nearest Neighbor search, which guarantees the mathematically closest matches but is computationally expensive, and Approximate Nearest Neighbor algorithms that trade a small amount of accuracy for significantly faster results on massive datasets.
They can choose between distance metrics like cosine similarity and Euclidean distance, because different models shape their vector spaces differently, and what counts as “close” depends on how the model was trained. They can also set confidence thresholds, meaning minimum score boundaries that filter out low-probability matches so that creative teams only review results meeting a high standard of relevance.
For searches involving specific lines of speech, the system applies a layered text analysis strategy.
Phrase matching with a configurable “slop” parameter, which controls how many words apart the search terms can appear and still count as a match, handles imperfect human memory. For example, if a user searches for a line from Stranger Things but remembers the wording slightly wrong, the system still finds the right scene.
Search-as-you-type functionality, powered by indexing partial word fragments at ingest time, surfaces frame-accurate results the moment an editor begins typing.
Linguistic stemming across multiple languages ensures that “running” matches scenes tagged with “run” or “ran,” collapsing grammatical variations into a single search intent. Fuzzy matching that tolerates character-level typos and misspellings accounts for transcription errors, so that high-value shots are never lost to minor data imperfections.
Raw search results need post-processing before they’re useful.
The system uses custom aggregations to cluster outputs, such as isolating the top 5 most relevant clips of an actor per episode. This prevents any single asset from dominating results and combats the fatigue that comes with reviewing hundreds of near-identical frames. The temporal reconstruction layer converts internal bucket boundaries back into natural scene boundaries, so editors see coherent scene-level results rather than arbitrary one-second slices.
The system also provides two result modes depending on the query intent. Union mode returns the full span of all matching annotations, prioritizing breadth and capturing any instance where a specified feature appears. Intersection mode returns only the exact overlapping duration where all criteria co-occur, prioritizing precision. The choice between them lies with the user.
Every architectural choice Netflix made carries a tradeoff, and the team was deliberate about which prices they were willing to pay.
Offline fusion means new content goes through a delay before it becomes fully searchable across all modalities. Netflix chose throughput over real-time freshness because the alternative, fusing data during ingestion, would bottleneck the entire pipeline.
For a production archive that grows by thousands of hours, that tradeoff makes sense. However, for a system that needed instant searchability, it would be the wrong call.
The toggle between exact and approximate nearest neighbor search is a direct precision-versus-speed tradeoff. Exact k-NN guarantees the mathematically best matches but becomes computationally expensive at scale. Approximate methods are faster but accept the possibility of missing some relevant results. Netflix surfaces this tradeoff to users rather than choosing them.
And the ensemble approach itself is a bet.
Running multiple specialized models and fusing their outputs through a three-stage pipeline produces excellent per-task accuracy, but it demands significant infrastructure complexity.
A single unified model would simplify the architecture at the potential cost of accuracy on specialized tasks. The fact that Netflix is simultaneously investing in both approaches, the ensemble pipeline and the MediaFM foundation model, suggests this tradeoff remains genuinely unsettled.
The current system implemented by the Netflix engineering team is the first phase of a larger vision. Three planned evolutions stand out:
-
First is natural language discovery. The system currently accepts structured query payloads, but the goal is to move toward fluid, conversational interfaces where an editor could type something like “Find the best tracking shots of Tom Holland running on a roof” and get results without needing to understand the underlying query structure.
-
Second is adaptive ranking. By building machine learning feedback loops that analyze how editorial teams interact with and select clips, the system would gradually self-tune its mathematical definition of relevance. The search engine would get better over time, learning from actual usage patterns rather than relying on static scoring algorithms.
-
Third is domain-specific personalization. A team cutting high-action marketing trailers has different relevance criteria than a team editing narrative scenes or conducting deep archival research. The system would dynamically calibrate search weights and retrieval behaviors to match the user’s context.
These extensions point toward a broader ambition of evolving from a search engine into an intelligent creative partner.
However, the current system already teaches a valuable architectural lesson.
When multiple AI models produce different kinds of data about the same underlying entity, the hardest engineering lies in the fusion layer. The models themselves are important, but the pipeline that persists, aligns, and indexes their outputs is what makes the whole system work.
Reference:
[ad_2]
Source link



